IR
Introduction
Definition von “Information Retrieval”
IR Model
Was ist Information Retrieval
- finden von material (meistens Dokumenten; von Artikel, Websiten, EMail, Bilder etc.)
- daten sind meist unstrukturiert (text dokumente, HTML, XML)
- relational datenbank wäre strukturiert (vor: Max, nach: Muster, age: 10)
- informationsbedürfnis (wie viele Einwohner in Paris; was gibts in Berlin; berlin Sehenswürdigkeiten - alle nicht präzise)
- präzise queries wäre
SELECT * FROM customers WHERE firstname = “wolfgang”
- präzise queries wäre
- innerhalb von großen collections (internet, archive)
Terminus Information retrieval
→ Zusammengefasst je Art des retrievens von elektronisch gespeicherten Daten
- uncertainty (Unsicherheit)
- fehlendes, falsches kann kommen
- man muss nicht alles zurück bekommen (”suche nach roten autos” → bei datenbank bekommt man genau alle matches und bei google ca. das was man sucht, biscchen blau auch mal ein rotes
- vagueness (Unbestimmtheit)
- die anfrage des Nutzers ist nicht so spezifisch wie zB bei einer Datenbankabfrage
Text Retrieval
- Anfragen die sich auf textuelle Inhalte beziehen (Websiten etc.)
- typischerweise Literaturdatenbanken, web search engines generell, zB Pubmed
- Fokus der Vorlesung
Application Examples
- Web search: google; Image search: unsplash; Enterprise search: TUD website, intra suche; Music search: Spotify; Code search: Github; Argument Retrieval: IBM (gegenargumente finden)
- Text-2-image Modelle: stück für stück Auswahl von Antworten (Bildern) nutzen um bessere Antworten zu generieren
IR Systeme
Struktur
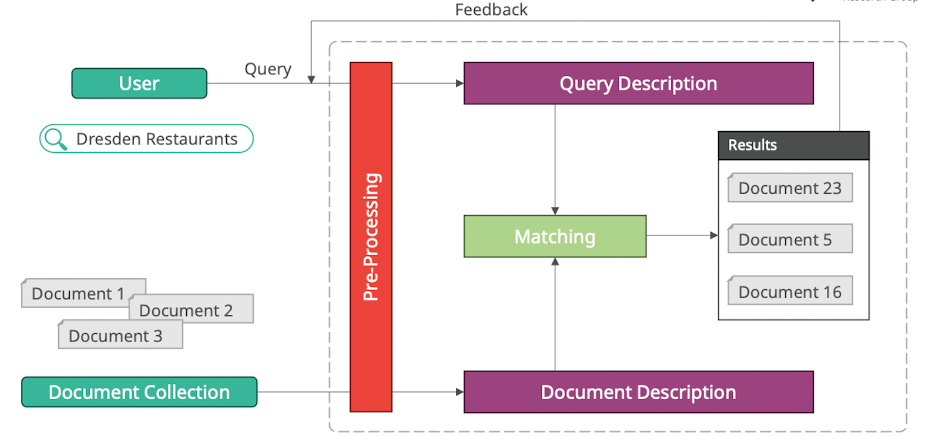
- Query (”Suchanfrage”)
- Ausdruck des Informationsbedürfnisses
- Pre-Processing (”Vorverarbeitungsschritt”)
- muss für Query und Document Collection jeweils gleich passieren
- Beispiele Schritte
- Encoding anpassen (zB alles zu utf8)
- Inhalte extrahieren (zB PDF → Text, Bild → Text)
- Normalisieren (zB alles klein schreiben)
- Document & Query Description
- internes format & daten struktur
- ist optimiert um schnell miteinander matchen zu können
- Matching
- sucht Dokumente die am relevantesten zu der aktuellen Anfrage passen (nicht die Exakten richtigen)
- vergleicht die Anfrage mit den Dokumenten
- Feedback
- wenn Nutzer nach Suche Sucheanfrage verändert dann kann man darauf schließen wie man ggf. Suchanfragen anpassen müsste / Vorschläge zu geben
- Rückkopplung auf neue Suchanfragen
Außerdem:
- Vocabular = Menge aller möglichen tokens
- Document = Menge von tokens der vocabulars
Questions
- Was sind die dokumente? Wie vorverarbeiten? Wie intern ablegen? Wie soll die suche aussehen? (Textsuche oder auch Filter etc) Wie effizient soll die Suche sein? Wie kann ich die Qualität bewerten?
→ gibt keine feste Antwort → kommt auf den Anwendungsfall an
Abgrenzung IR und Datenbank
- Datenbank:
- liefert exakte Matches, ist deterministisch, Abfragesprache (SQL)
- schwierig zu bedienen, aber genau die ergebnisse die angefragt
- daten müssen kuratiert sein
- select * from pflanzen where gattung = “obstbaum” (nur genau pflanzen der gattung)
- IR:
- liefert möglichst beste Matches (relevante), is probabilistisch, natürlichsprachlich
- einfach zu bedienen aber keine festen ergebnisse
- daten können irgendwie unstrukturiert sein
- web search: fruit tree (alles mit thema fruit tree, ruit tree würde auch verstanden werden, vielleicht ein eintrag duden etc.)
Research aktuell
- Transformer seit 2019 erlauben es ir modelle viel besser zu funktionieren (neuronale Netzwerke die die Bedeutungsebene verstehen)
- Google und Bing größte Qualitätsverbesserung
- 2022 ChatGPT
- RAG: erlaubt Zusammenfassung durch LLM der top 10 ergebnisse
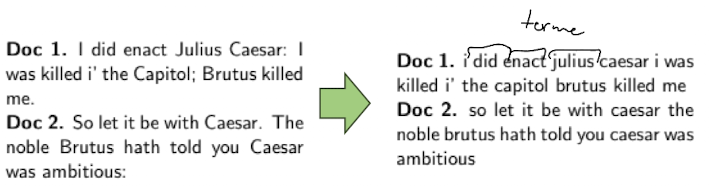
Block I: Document Processing: Vocabulary, Terms, Tokenization, Normalization
Documents
Documents
- Annahme: wie wissen was Dokumente sind, wir können diese als machinen lesen
- Parsing von documenten
- Sprache, Encoding, format (pdf, word, excel), leserichtung
Format/Language Complications
- Was machen wir wenn ein Document verschiedene Sprachen hat (Email in Spanisch, Anhang Französisch)
- Welche document Einheit für indexierung?
- One file = ein Dokument / n Dokumente
- n files = ein Dokument (Latex in HTML)
→ nicht trivial was ist ein Dokument
Definitions
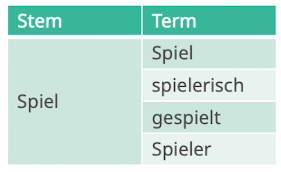
Token = Individuelles wort in text (syntaktische Einheit)
Term = Individuelles word in text Vokabular (nach einer Normalisierung, das wird indexiert)
Morphem = kleinste grammatikalische Einheit in Sprache (laufen → lauf ist Worstamm, Morphem)
Inflection = Beugung der Wörter (Fälle)
Basic Form = Grundform, Wort ohne Beugung
Derivation = Wörter zusammensetzen mit prefix und suffix -ness -un
Compound = Wort aus mehr als einem Stamm zB Dampfschiff
Noun Phrase = Phrase die as Head ein Substantiv hat
Tokenization
Was ist ein Wort?
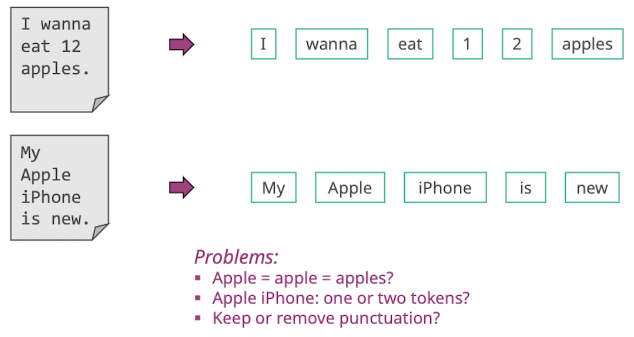
- Probleme
- 1 2 oder 12
- wanna zu want to
Tokenization Problems
- One word or two
- Data base; State-of-the-art; San Francisco; Hewlett-Packard
- Elimination of stop words
- Wörter of semantische Bedeutung sollten entfernt werden (bis zu 50% der Token)
- Yesterday, I too a Vitamin A pill
- End of sentence vs abbreviation
- Contraction (I’m I am - wont will not)
- Numbers
- 3/20/91; 20/3/91; Mar 20, 1991; B-52; (123) 234-233
- Apostrophes can be part of a word
- can’t, don’t, master’s degree, 80’s
- Special characters
- URL, code
- Capitalized word can be different
- Brush vs brush
- Apple vs apple
- Chinese - keine Leerzeichen; je nach context bedeuten die Zeichen unterschiedliches
- Japanisch - verschiedene Sprachsysteme die zusammen arbeiten
- keine Leerzeichen - auch bei Deutsch, Switzerdeutsch
- Akzente - resume vs rèsumè; Akzente
Normalization
Idee: Unterschiedliche Ausdrücke auf eine gleich normalisierte Basis bringen
Normalization
- sowohl Query als auch Dokumente müssen gleichermaßen normalisiert werden
- für Klasse von Wörter Äquivalenzklasse definieren
Techniken
- Wörter werden grammatikalisch markiert um unterschiedliche Formen/Beugungen zu erlauben
- Stemming → Fokus on syntax (geh
en→ geh)- Algorithmen die gegeben ein Wort auf den Wortstamm reduzieren
- “zerheckseln” wirklich abschneiden
- e.g. foxes → fox; flies → fly
- Easy, da wegschneiden
- Lemmatization → Fokus auf semantik (er geht → gehen; er ging → gehen)
- Rückführen auf die kanonische Form (Grundform) eines entsprechend Wortes
- Komplexer als Stemming
Vorbereitung: Case Folding & Stop Words
- Case Folding: alle Buchstaben als Kleinbuchstaben (Nutzer müssen bei suche nicht auf Kapitalisierung achten; weniger Speicher; → nicht indiziert)
- Stop Words: häufige Verbindung Wörter mit wenig inhaltlichen Mehrwert
- a, and, an, are, as, at …
- wird wieder indiziert von search engines
Weitere Äquivalenzklassen
- Soundex → ähnlich klingendes
- Thesauri → semantisches
- Transliteration → alphabete replacen (griechische zu normal)
- Probleme → wenn durch symbolstellung wie im chinesischen inhalt abweicht
Stemming
- Idee: Wortende abschneiden um Wortstamm zu finden
- aber: Fehleranfällig, Sprachabhänig, oft Inflectional und derivational

- aber: Fehleranfällig, Sprachabhänig, oft Inflectional und derivational
Stemming: Table Lookup Approach
- Mapping von Termen zur Wortstamm
- Sehr aufwendig den Table aufzubauen, Speicherintensiv
- Praxis: für fachterminie, wo sehr zuverlässiges Mappig gebraucht wird
Stemming: Successor Variety Approach
- Idee: Wortstamm ist wie Stamm eines Baums, an bestimmten Punkt fächert Baum auf. Um Stamm zu finden Punkt finden wo der Baum auffächert
- Die Klippe zeigt, wo sich das Verhalten sich signifikant Ändert, Äste sind fertig.. Wortstamm gefunden


- Stück für Stück prefix anschauen und schauen was laut Korpus als nächster Buchstabe vorkommt
- für R: 1: READ, READABLE, READING, RED ; 2: ROPE; 3: RIPE
N-gram Stemmers
Idee: jedes wort in n-großes fenster zerstückeln
- Bi-Gramm:
- statistics → st ta at ti is st ti ic cs
- davon die uniquen: st ta at ti is ic cs
- statistical → st ta at ti is st ti ic ca al
- davon die uniquen: st ta at to is ic ca al ti
- similarity mit Dice coefficient

- man kann sich dann eine Ähnlichkeitsmatrix aufbauen
- statistics → st ta at ti is st ti ic cs
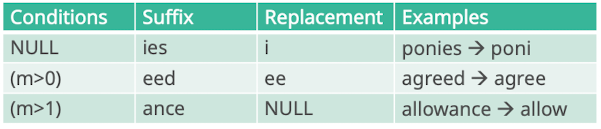
Affix Removal Stemmers
- Idee: Regelwerk wie man von rechts kommend dinge ersetzt um Stück für Stück zum Wortstamm zu kommwn
- gibt einige, Porter Stemmer ist sehr gut und state of the Art
Porter Algorithm
- eine Menge von bedingten Regeln
- 5 Phasen
- 1 Plural und past participles entfernen
- 2-5 English deals with English specific suffixes
- Bsp.

Lemmatization
- Idee: auf volle Grundform zurück, nicht auf den zerheckselten Wortstamm (wie bei Stemming)
Stemming effectiveness
- für manche queries macht es effectiver für manche nicht
- je nach Sprache bringt unterschiedlich viel
- Englisch gut; Deutsch aufwendiger
- Sprachen ohne konjunktion easy (asiatisch); Arabisch sehr hard
- vocabulary with von 10 bis 50% reduziert
- ABER

Linguistic Annotation / Part-of-Speech Tagging
→ Motivation
Linguistic Annotation / POS
- Motivation: Um die Bedeutung der Wörter rauszubekommen, Funktion der Wörter hinsichtlich ihrer Grammatik anschauen
- Idee: Zuweisen der Rolle des Wortes
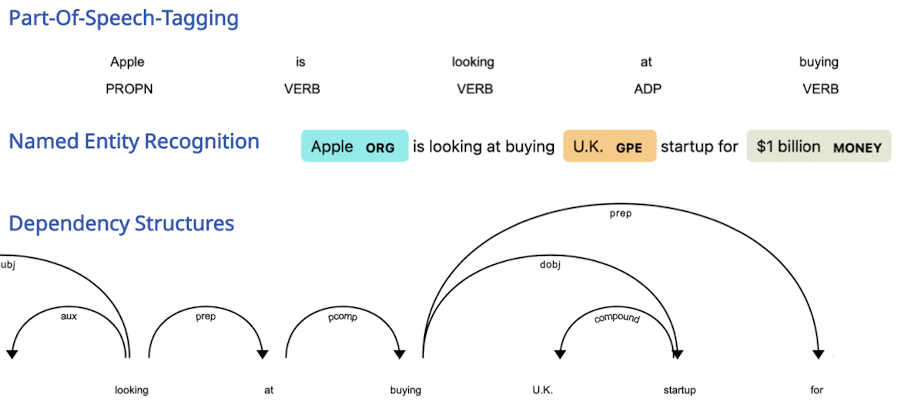
- POS tagging - zuweisen der Rolle
- Regelbasierte Tagger
- Stochastic Tagger
- Simple stochastic tagger
- Idee: jedem Wort wird der in Vergangenheit meist zugewiesen Tag zugewiesen
- Problem: Wörter einzeln richtig getaggt, aber tag sequenzen unpassend
- HMM Tagger
- Simple stochastic tagger
- Neurale Network Tagger (Transformer etc.)
- Named Entity Recognition - bestimmte Teile werden getaggt in zB ORG, Land, Datum, Wert
- Große Datenbank im Hintergrund von Entitäten
- Unternehmen, Orte, Währungen, Personen
- Ansätze wie beim POS tagging
- Große Datenbank im Hintergrund von Entitäten
- Dependency Parsing
- Idee: Verb ist zentrales Ding im Satz, aufbauen eines Abhängigkeitsgraphen um Struktur vom Verb aus aufzubauen
Block I: Document Processing: Dictionaries and Tolerant Retrieval
Motivation: Wie repräsentieren wir das Vokabular als solches, was können wir damit machen (Wildcard), Wie kann man queries korregieren wenn term nicht vorhanden (Spelling Correction, Soundex)
Dictionaries
- Datenstruktur die alle terms der indexed documents beinhaltet
- Aufbau der Datenstruktur: memory efficient, fast lookup time
Datenstruktur Dictionary
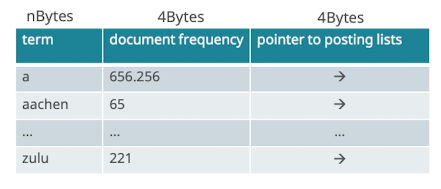
- Posting liste: liste wo der term mindestens einmal vorkommt
- Meistens als hashtable oder tree umgesetzt
- je nachdem ob daten dazu kommen (wenn ja, tree)
- daten statisch? dann hash → schneller zugreifen
- wildcard search mit hash nicht möglich
- Hashtabelle
- query: hash query term, resolve collisions, locale entry in fixed-width array
- Lookup log1
- Baumstruktur
- Vokabular wird auf prefixbaum aufgebaut
- Binärbaum oder pro Buchstabe ein zweig gibt verschiedene
- Lookup logM
- Treap (tree + heap)
- zufälliges gewicht → sorgt für in erwartung balancierten Bauem
Wildcard queries
Wildcard Queries
- trailing wildcard (prefix)
- zB mon*
- mit dem was ich weiß dem Baum (B-tree dictionary) absteigen, dann alle sub als qualifizierende Teilergebnisse
- terme: mon ≤ t < moo
- leading wildcard (suffix)
- zB *mon
- alle Terme spiegeln, dann in die Baumstruktur (reverse B-tree), dann im baum wie prefix suchen (n-o-m)
- term: nom ≤ t ≤ non
- wildcard in middle (asterix)
- zB m*nchen
- Optionen
- m* (in B tree) und *nchen (in reverse B tree) und dann vereinigen der beiden menge (schnittmenge)
- ist aber Aufwendig, Mengen sollten sortiert werden, bei m* sind schon sehr viele machtes
- permuterm index
- nicht nur term, sonder auch der permutiertes, durch rotiertere term jeweils speichern im dictionary

- für die Query: hel*o → look up o$hel*
- damit wird die Sucher zu einer Prefix suche
- wird aber selten in der praxis verwendet
- vervierfacht den Speicher
- nicht nur term, sonder auch der permutiertes, durch rotiertere term jeweils speichern im dictionary
- m* (in B tree) und *nchen (in reverse B tree) und dann vereinigen der beiden menge (schnittmenge)
k-gram (bigram, trigram, …) Indexes
- speichereffizienter
- alle chars werden als k-gram repräsentiert in einem term
- zB “April is the cruelest month”
- $a ap pr ri il l$
- $i is s$
- …
- maintain a inverted index from bigrams to the terms that contain the bigram
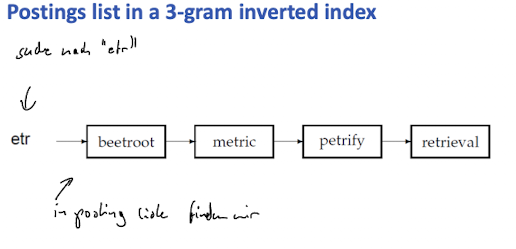
- Achtung: inverted index gibt es sowohl für n-gram zu term als auch term zu document
- Wildcard Anfrage in bigram index
- mon* kann via [$m AND mo AND on] aufgelöst werden, jeweilige posting listen werden Vereinigt
- findet alle, aber gibt aber auch falsch positive wie “Moon”
- kann nochmal filtern
- im vergleich zu permuterm index
- braucht weniger Speicher
- Permuterm brauch kein post filtering
Spelling Correction
Motivation: in Daten die wir haben gibt es schreibfehler etc. unstrukturierte daten unstrukturierte Anfragen, gegenteil von Datenbanken
- Das entfernen von scheinbaren Schreibfehlern kann sinnvoll sein, aber manchmal will ein Nutzer genau das suchen
- Zwei Anwendungsfälle
- die Indexierten Dokumente korrigieren
- die Anfragen korrigieren
- Zwei Methoden
- Isolated Word - jedes Wort wird unabhängig gecheckt
- Context-sensitive - surrounding words werden beachtet
Correcting Documents and Queries
- Correcting Documents
- Überlicherweise geht man davon aus das die Dokumente richtig sind
- nur OCR wenn benötigt
- best practise: Dokumente sollten nicht verändert werden
- Überlicherweise geht man davon aus das die Dokumente richtig sind
- Correcting Queries
- isoliert die Wörter korrigieren
- Premise 1: liste von korrekten Wörter
- Premise 2: abstand von falsch geschriebenen und richtigen wörter
- → das mit der kleinsten distanz ist das korrekte wort
- Alternative:
- Duden etc. nutzen als korrekte Wortbasis
Distances
- Abstand zwischen richtigen und falschgeschriebenen Wort
- Edit distance wie Levenshtein distance, Weighted edit distance, k-gram overap
- Levenshtein distance
- Zählen von Operationen die benötigt werden um von einem ins andere Wort zu kommen (ins, del, rpl)
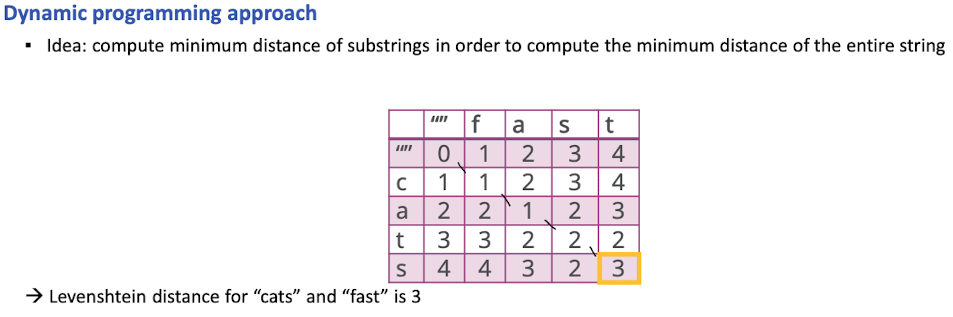
- Berechnung
- Zählen von Operationen die benötigt werden um von einem ins andere Wort zu kommen (ins, del, rpl)
- Weighted edit distance
- wie bei Levenshtein, aber wir gewichten die Buchstanden nach typewriter distance (Abstand auf der Tastatur)
Spelling Correction (isoliert)
- Problem wenn wir für jede query zu allen möglichen Wörter (> 1 mil) die levenshein distance berechnen, wird es zu viel
- Lösung: k-gram index um zu bestimmen wie Ähnlich sich zwei Wörter sind
k-gram Indexes for Spelling Correction (isoliert)
- query term wird in all k-gramme indexiert
- misspelled word “bordroom” → zB bigram: $b, bo ,or, rd, dr, ro, oo, om, m$
- dann die Terme aus den posting listen des index holen → Schnittmenge
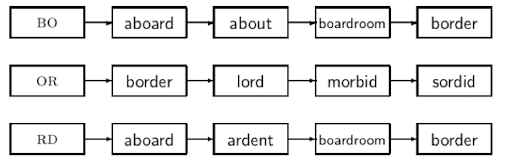
- x Wörter matchen
- anschließend post-filtering schritt: Jaccard coefficient
- wie groß ist das overlap der beiden Mengen an bigrammen von wort zum verglichenen
- Treshhold ob das wort nah dran ist laut jaccard
Context-Sensitive Spelling Correction
Jetzt nicht mehr isoliert, sondern mit context…
- zB “flew form Munich” → IR merkt irgendwie wenig Ergebnisse → muss korrigieren
- hit based spelling correction
- alternative Schreibweisen für jedes Wort finden
- flew → flea
- from → form
- munch → munich
- dann alle Kombis ausführen und schauen wo die meisten Ergebnisse /hit
- → ABER skaliert schlecht
- Alternative: schauen was bisher so gesucht wurde → dafür müssen wir Anfragen loggen/sammeln
- generelle Probleme
- Benutzeroberfläche: automatisch vs anzeigen, simple vs powerful, vielleicht wollte der Nutzer den typo
- Kosten: Berechnung kostet, muss das auf jeder query laufen? nur auf querys die wenig Ergebnisse
Soundex
Idee: falsche Schreibweisen erkennen, da Person Aussprache falsch in Text transkribiert hat
- Soundex erlaubt umwandeln des Terms in einen “phonetic hash”
- 4 char reduced form
- Indexed Tokens umwandeln und Query terms umwandeln
- → Index kann vergleichen
- Algorithmus
- erstes Zeichen bleibt erhalten
- alle vokale + HWY als “0”
- alle B,F,P,V zu “1”
- und so weiter
- …Buchstaben die ähnlich klingen werden ersetzt
- Entfernen aller Dopplungen
- Entfernen aller “0”
- Mit 0 hinten bis 4 Zeichen auffüllen (sodass Zeichen + 3 Ziffern)
- Mittlerweile gibt es besseres, aber ist nicht schlecht
Block 2: Boolean Retrieval, Phrase Queries, and Positional Indexes
Motivation: Matching anschauen des IR Models, wie bauen wir den Index auf für das matching
Boolean Retrival
“Einfachste Form wie man sucht”
- Queries sind Boolsche Expressions [CAESAR AND BRUTUS]
- Suchmaschine gibt alle Documente diese diese Expression satisfien
- zB BRUTUS and CAESAR but not CALPURNIA
- Grep ist nicht die Lösung:
- Slow (für große Collection)
- Zeilenorientiert
- Not xyz → nicht trivial
- Lösung: brauchen ein Index den wir vorher aufbauen
- Grep ist nicht die Lösung:
Termin-Document Incidence Matrix

- Idee: überall wo mindestens einmal term drin ist, 1 bzw. 0
- Beispiele Suche:
- BRUTUS AND CAESAR
- die jeweiligen Zeilen als Bitliste verschneiden
- BRUTUS AND CAESAR AND NOT CALPURNIA
- eine negierte Zeile für Calpurnia (complement)
- dann wieder jeweils verschneiden
- BRUTUS AND CAESAR
- Problem:
- N=105 Dokumente mit je 1000 words/tokens → 6GB Speicher
- halbe trillionen Einträge
- 0,02% sind mit 1 → sparse
- Für viele Wörter sind die meisten Dokumente mit 0 belegt (kommen nur selektiv vor)
- → wir wollen nicht die ganzen 0 Speichern → super lange bitlisten → verschneiden bei sehr vielen Dokumenten nicht einfach
- N=105 Dokumente mit je 1000 words/tokens → 6GB Speicher
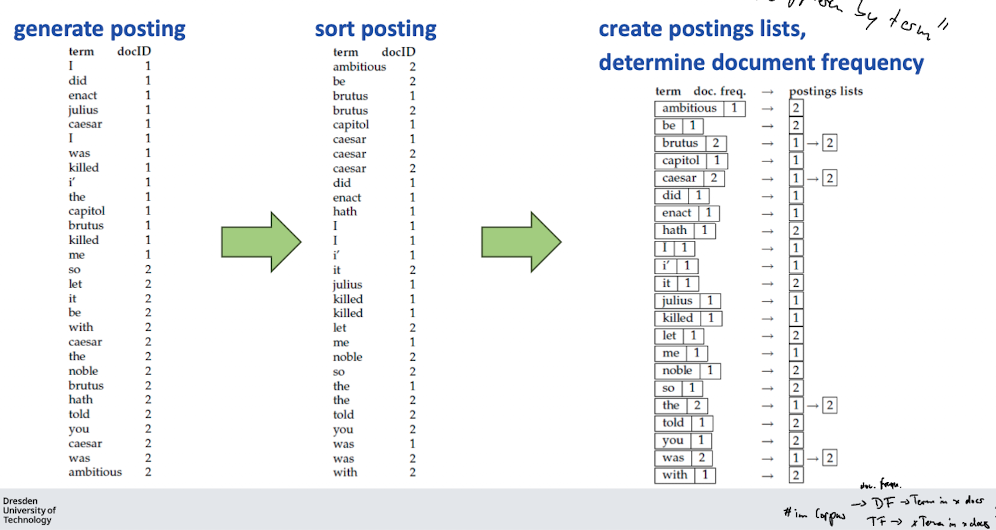
- Idee: inverted index
Inverted Index
- Idee: jedes dokument bekommt eine Id; für jeden term t aus dem vokabular haben wir einen Zeiger der auf eine Liste (”Postingliste”) zeigt in welchen die Document Ids drin sind.
- “einfach verkettete Listen”
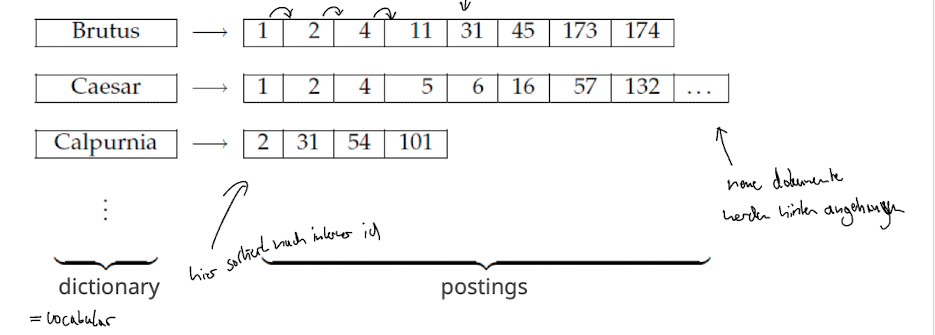
- Schritte zum Aufbauen


Processing Boolean Queries
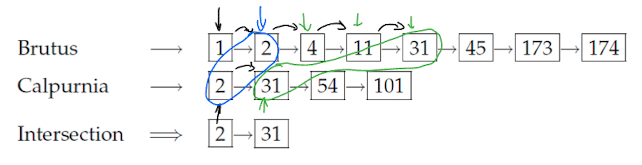
Simple Conjunctive Query (two terms)
- Beispiel: [BRUTUS AND CALPURNIA]
- BRUTUS Eintrag finden (zB durch Blätter im Baum), posting Liste abrufen
- CALPURNIA Eintrag finden, posting Liste abrufen
- Verschneiden der beiden Listen
- Schrittweiser Vergleich, wenn ich gleiche Ids dann treffer bis Ende einer Liste angekommen
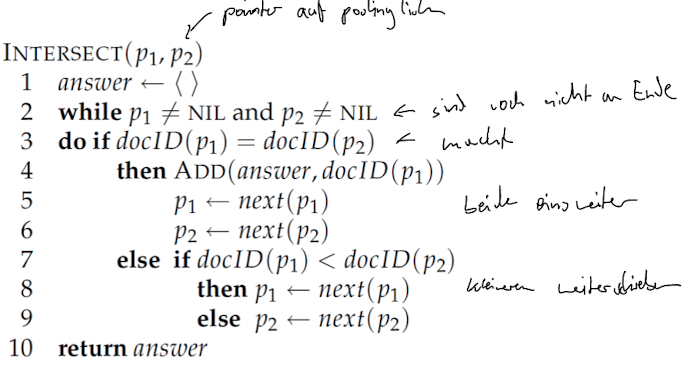
Query Optimization
Motivation: wenn nun ein 3. Term kommt, können nur Binäre Joins
- BRUTUS AND CALPURNIA AND CAESER
- Was ist bester reinfolge? (a and b) and c oder (a and c) and b…?
- Heuristic: Mit der kürzesten posting listen aufsteigend beginnen
- Dafür auf die Documents Frequency zugreifen (bereits pro Eintrag abgelegt)
- weitere Optimierungen
- Größen von Zwischenergebnisse abschätzen etc.
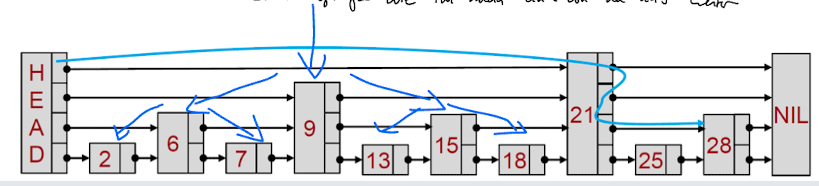
Skip Pointers
Motivation: hinsichtlich basic intersection algorithm, wir wollen bei dem Schrittweisen Vergleich möglichst schnell zu den Matches kommen, nicht step=1
Idee: schneller Springen, Einführen von Springpointern
- Beim indexing skip pointer mit erstellen
- Jedes Element hat 2 Pointer: zu nächstem Element und zu geskippten Element
- erlaubt effizienter zu verscheiden
- Fragen:
- Wo skip pointer platzieren/ wie groß abstand
- nicht überspringen, trotzdem fortschritt machen
- Wo skip pointer platzieren/ wie groß abstand
- Lösung: Skiplist

- Ganz unten normale Posting liste
- Für die postingliste länge P root(P) gleichmäßig verteilte skip pointer
- Noch Pointer auf unterschiedliche Skipgrößen
- hat Geist einies Binärensuchbaums (9 und dann je nach größer kleiner weiter springen)
Boolean Search
Boolean Queries
- kann jede Boolsche Expression beantworten
- jedes Dokument passt oder nicht; nur genau die Ergebnisse die man sucht
- Anwendungsfall Enterprise suche; Anwälte
- zB Westlaw
- Möglichkeit von proximity operatoren …
- query: “trade secret” /s disclos! /s prevent /s employe!
Recap: für spezielle Use cases passend… wie gehen wir mit Schreibfehlern um, oder synonymen… boolean sagt nur ist der term da oder nicht… kein scoring
Phrase Queries and Positional Indexes
Motivation: Anfrage: “stanford university” als phrase → “the inventor stanford ovshinsky never went to university” sollte nicht matchen
- Nutzer erwarten das die reihenfolge der Anfrage beachtet wird
- Dafür funktioniert unser bisherige invertierter Index nicht
- Lösungen: Bi-word Index oder Positional Index
Bi-Word Index
- “auf der linken Seite nicht mehr einzelne Terme sondern die Kombinationen”
- bi-words als index Einträge → dies erlaubt die einfache Beantwortung von zwei wort Phrasen Anfragen
- Longer phrase queries
- bei “stanford university palo alto” wird dann “standford university” AND “unitversity palo” AND “palo alto”
- sollte gut funktionieren, aber falsch positive möglich
- post-filtering muss auf 4-wort Phrasen filtern
Extended Bi-Words
- nur Kombinationen von Substantiven indexieren, da Nutzer meist auch ohne präpos und Artikeln suchen
- dazu wörter via part-of-speech tagging als substantive, verben etc. taggen
- in der Praxis eher selten
- falsch positive; index wird sehr groß
- dann eher: positional index
Positional Index
- Idee: position wo der term in dem dokument drinne steht
- “to be” → “to” an stelle 16 und darauf an stelle 17 “be”
- Suchen die Dokumente wo die Position aufeinanderfolgt

Proximity Search
- wird durch positional Index ermöglicht
- wort x mit abstand von y wörtern zum wort z
Combination Scheme
- in der Praxis macht auch eine Combi aus Bi-Word und positional sinn
- oft gesuchtes “barack obama” nicht als bi-words (da individuelle wörter immer zu phrase gehören)
- “the who” dann als bi word
Block 2: Vectorspace Model, Working with the Inverted Index
Why rank Documents?
- Bisher angeschaut: Boolean Retrival - Dokumente passen oder eben nicht
- gut für Experten, aber nicht für den typischen Anwender
- wollen nur wenige, möglichst gute Ergebnisse auf einmal
- BR problem: feast or famine (200000 vs 0 results) → braucht skill um die Anfragen passend zu formuliern
- Lösung: Ranked Retrival (egal wie viele Ergebnisse, nur top-k zeigen, Nutzer nicht überlasten)
Scoring
- Basis des Ranked Retrieval
- Idee: relevate bekommen höheren Score als unrelevante
- wir wollen einen Wert zwischen 0 und 1
- 1st Step
- wenn term in doc nicht vorkommt dann score 0
- umso öfter term vorkommt desto höher der score
Jaccard
- Berechnet den overlap von zwei Mengen
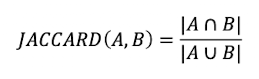
- Problem: kurze Dokumente werden bevorzugt, term frequency und rarität (mehr information) wird nicht beachtet
Term frequency
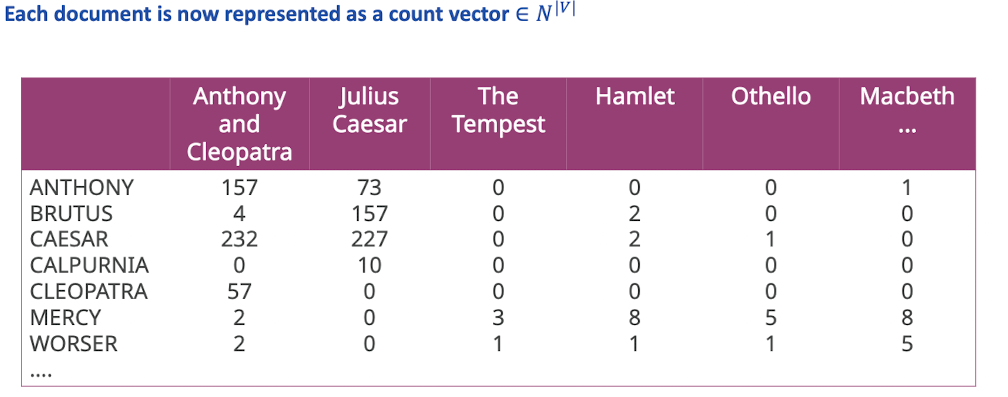
- Bag of Words Model: Reihenfolge wird nicht beachtet (erstmal Rückschritt zu positional index)
- Def: Term Frequency tf eines terms t in document d (Anzahl der Vorkommnisse)
-
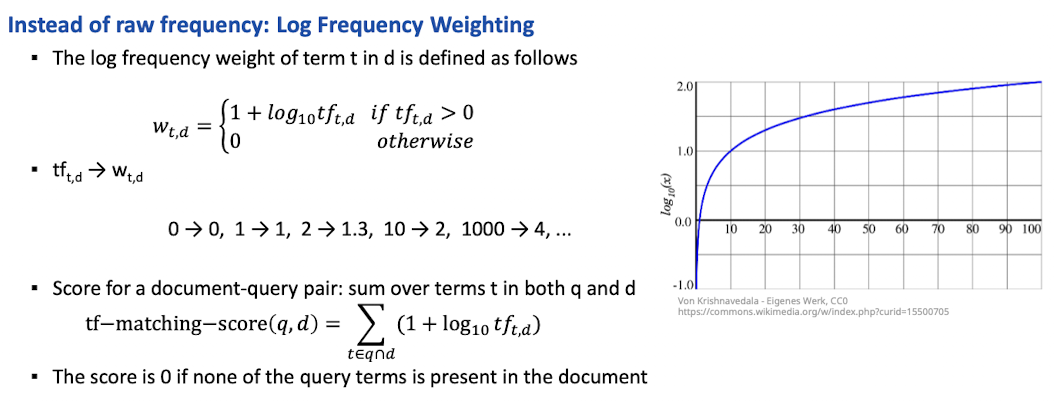
- Idee: Wir wollen diese für das scoring benutzen, tf=10 ist relevanter als tf=1
- Problem: aber nicht 10x (nicht proporitonal)
- Lösung: Log Frequency Weighting
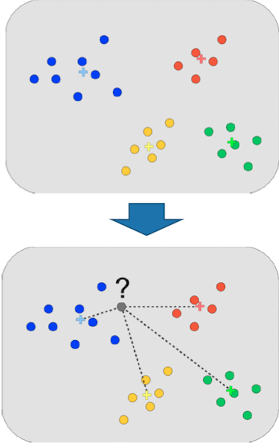
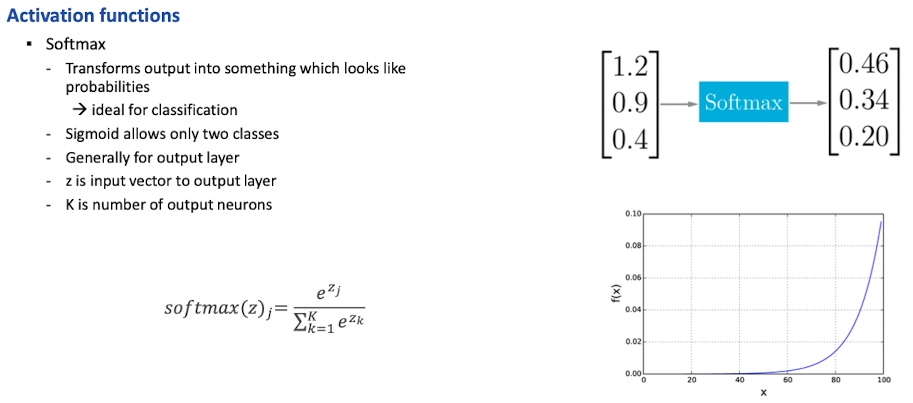
tf-idf weighting
Motivation
- neben term frequency (im doc) auch noch frequency in gesamter collection
- wir wollen hohe weights für rare terms (ARACHNOCENTRIC)
- wir wollen kleinere weights für oft vorkommende terme (GOOD, LINE, INCREASE)
Document Frequency
- inverse document frequency of term t (N is number documents in the collection)
- “how informative is it”
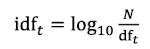

- Auswirkung auf ranking
- “arachnocentric line” mehr gewicht auf docs mit arachnocentric
- bei one-term queries kein effekt
- → idf globales & tf locales gewicht
- Collection Frequency: #tokens of t in collection (counting multiple)
- Documents Frequency: #documents t occurs in
tf-idf
- Idee: locales (term frequency) und globales (inverse doc frequency) gewicht kombinieren
- Bestes weighting Schema in IR
- Wird höher wenn mehr verkommen innerhalb eines Dokuments (tf)
- Wird mit der Rarität innerhalb der Collection höher (idf)
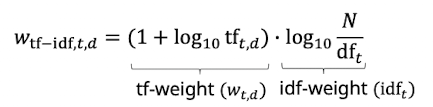
Document Vector
- Wir geben ein tf-idf Gewicht jeden term t in jedem document d
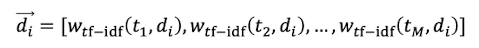



The vector space model
- neue Repräsentation unlocked
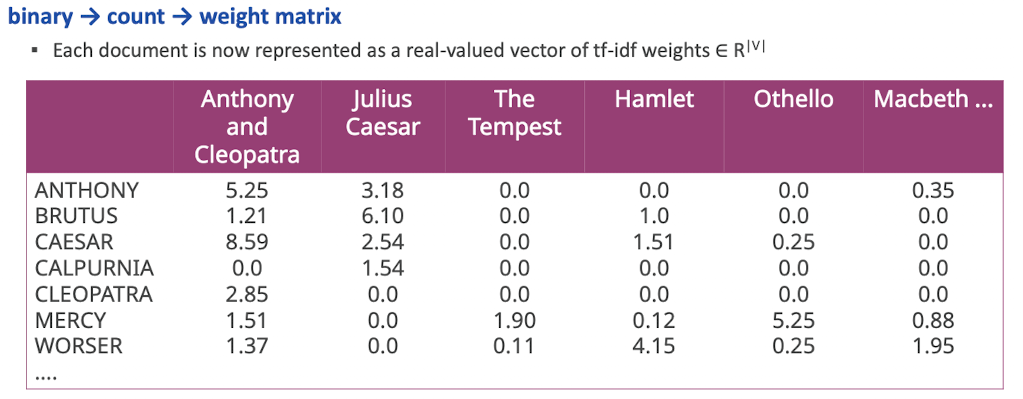
- Jedes doc ist ein vector
- ein |V| dimensionaler Vektorspace
- Terme sind Achsen und Document Punkte/Vektoren im Space
- sparse space (viel 0)
- Ideen:
- Anfragen auch als vector darstellen
- Dokumente ranken nach Ähnlichkeit dazu
Vector Space Similarity
- Wie umsetzen?
- Euclidean distance? Bad idea, large for vector with different length
→ Idee: Winkel anstatt Abstand
- Length Normalization (damit die Berchnung von dem Winkel einfacher wird

- alle Vektoren werden auf die Länge 1 normalisert
Cosine similarity
- repräsentiert wie ähnlich sich die Winkel sind
- grundlage:

- da wir normalisiert haben, wird es einfacher:
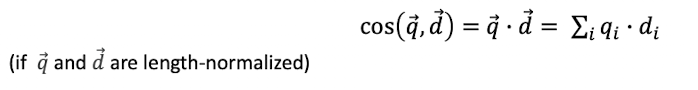
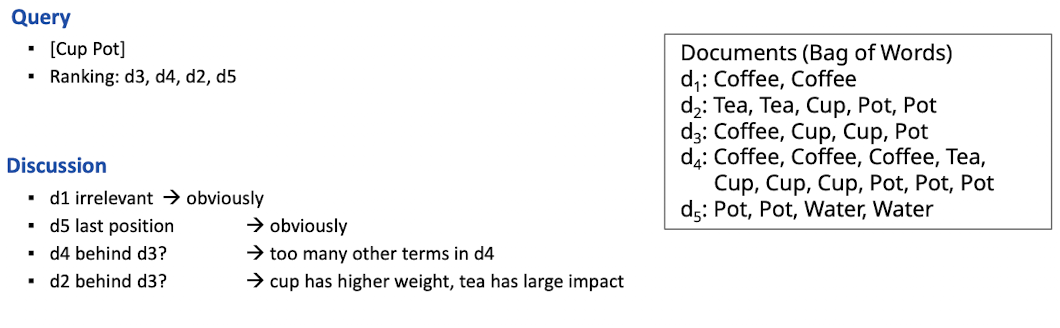
- Beispiel:


Variant tf-idf functions
- gibt verschiedene Möglichkeiten
- tf-idf zu Gewichten (natürlich, logarithmisch, augmented, boolean, log avg)
- document frequency (no, idf, prob idf)
- Normalisierung (cosinus, byte size)
- Wichtig:
- documente und suchanfragen gleich normalisieren und gewichten
- Normalisierung wichtig! (effizient berechnen, und kurz und lange docs gleich behandeln)
- kann man als SMART Notation notieren (3 Stellschrauben)
Working with the Inverted Index: computing tf-idf
Motivation: wie können wir das konzeptionelle nun implementieren mit dem Index den wir kennen
Query Processing and Optimization
“Wie tf-idf Gewicht für eine Suchanfrage berechen?”

“Bilden des Skalarprodukts der idf Gewichten multipliziert mit den tf Gewichten, das ganze nur für die terme die in der Suchanfrage vorkommen”
- nur Query Terms anschauen
- idf-Gewichte hängen von query term t ab
- td-Gewichte hängen von query term t + doc d ab
→ Was können wir vielleicht schon vorberechnen?
- so machen das wir wenn wir nur top-k brauchen auch vielleicht nicht den ganzen Index durchschauen müssen
- Lösungen: Term-at-a-Time / Document-at-a-Time
Term-at-a-Time
- für jeden Term berechnen wir tf-idf
- Ausgangspunkt (w_idf is vorher berechnet)
- Für Suchanfrage “car insurance cheap”
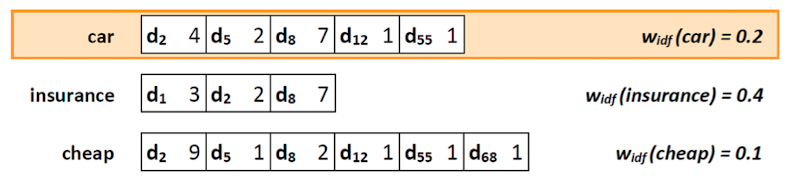
- tf-idf Wert für car für alle docs berechnen

- tf-idf Wert für insurance für alle docs berechnen (+ bereits gefundene von vorher)

- (cheap..)… jetzt Ranking über k=3 (3 größten)

Document-at-a-Time
Motivation: alternative zu TaaT, müssen nicht immer gesamte posting liste durchlesen, finales ergebnis erst ganz zum schluss → hier effizienter
Idee: posting liste für verschiedene Terme parallel lesen
- Posting listen müssen nach doc nummer sortiert sein
- parallel lesen der ersten Einträge der ersten Spalte
- dadurch das sortiert, d1 ist für car und cheap schon raus → können für d_1 schon tf-idf berechnen (0,3*0,4=1,2)
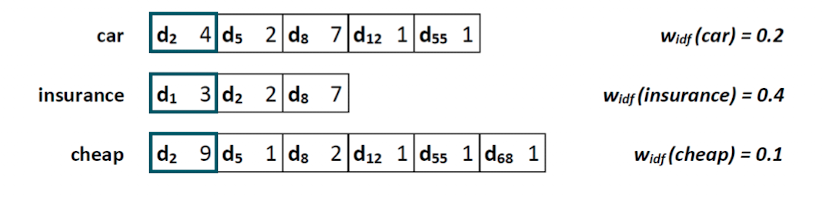
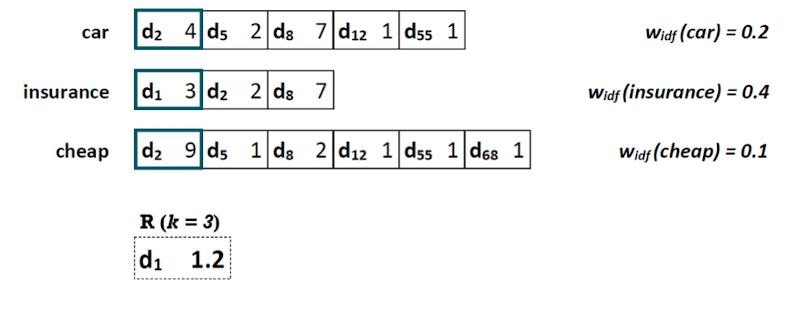
- dann wenn alle d_2 gesehen, finaler score von d_2 direkt berechnen

- und so weiter

- Wir können aber noch etwas optimieren
Top-k Query Processing with NRA
- Idee: posting liste nach Häufigkeit des terms pro doc sortieren
- wieder lesen in Parallel, in absteigender Reihenfolge der termfrequenz
- zwischendurch Mathematische Grenzen berechnen, ab welchen Punkt muss ich nicht mehr weiter schauen
- was kann maximal noch dazu kommen
- Bis zu dem Strich alles gelesen, d_8 kennen wir, wissen schon das 4.4 gefunden, es wird mit Sicherheit kein besseres geben, C mit Zwischenergebnisse


- unterste grenze, kann nicht weniger werden
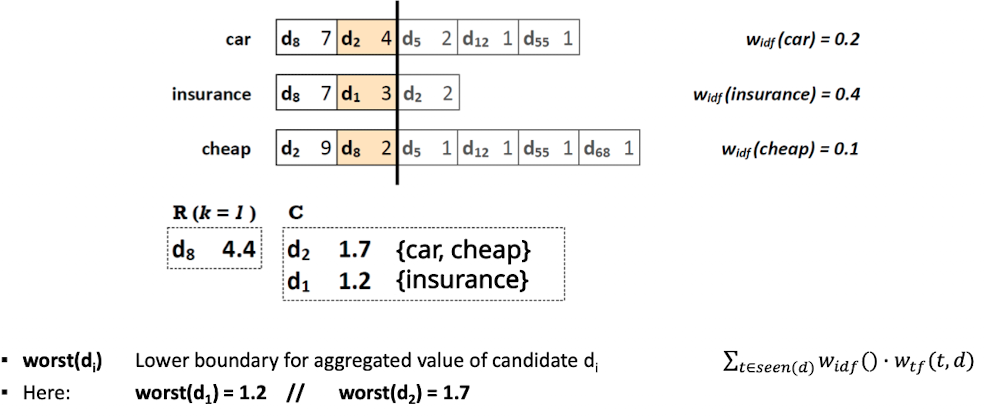
- bestes outcome

- für alle docs die nicht in der C liste sind
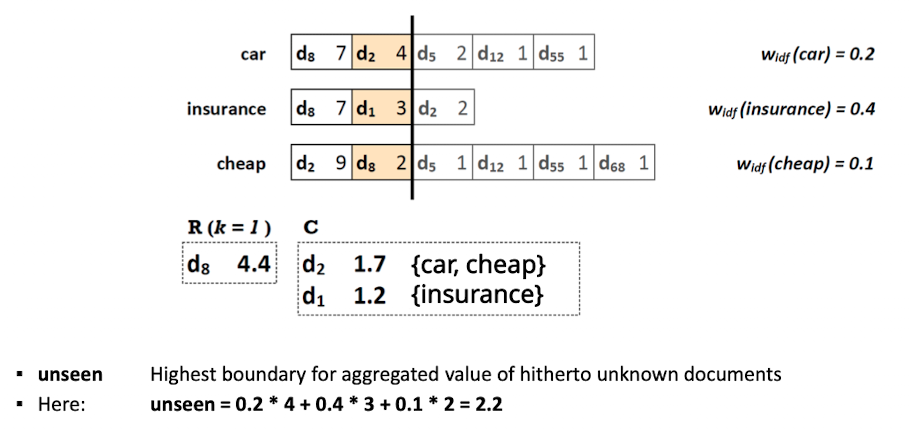
- jetz wissen wir das d_1 und d_2 kleiner als die 4,4 (wollen nur k=1) d_1 und d_2 werden nicht besser und die nicht gelesen können es auch nicht schaffen
- Die Schranken ermöglichen uns frühzeitig abzubrechen
Dynamic Indexing
- Probleme: neue Documente (wie Zeitungen, Websiten) kommen dazu, verschwinden
- → Index muss sich ständig ändern
- Frage: Wie können wir posting liste anpassen?
- Naive: posting liste aktualisieren → geht nicht im großen Stil, da zu aufwendig
- Lösung: Delta Index
- Veränderungen in delta index schreiben
- Einmal pro Tag Merge machen und Normalenindex anpassen
- zu Ausführung in Hauptindex + delta schauen
Block II: Evaluation and Result Summaries
Unranked Evaluation
- Motivation: wir wollen beurteilen wie gut ist uns IR system?
- Was kann man messen?
- Wie schnell ist der index mit neuen docs?
- Wie schnell ist die suche?
- Was kostet der Betrieb?
- → meist wichtig aber nicht direkt messbar: Nutzerzufriedenheit (sehr wichtig, relevante Ergebnisse
- je nach Anwendungsfall verschiedene Nutzer denkbar
- wie Relevanz von Ergebnissen messen?
- benchmark daten für: collection, queries, eine Zuordnung für relevant und nicht relevant für document query paare
- Achtung Query ≠ dem Information need !
Precision and Recall
Precision (p) = wie viele der Ergebnisse sind relevant
Recall (r) = wie viele relevante Ergebnisse der relevanten items
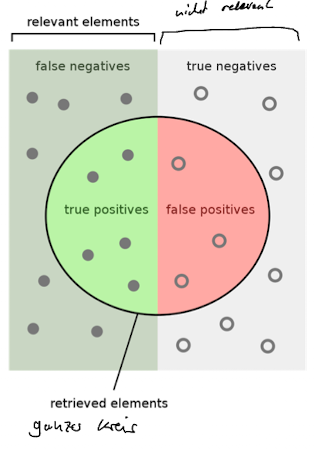
- Precision / Recall tradeoff
- recall kann erhöht werden wenn man mehr dokumente returned
- high precision for a very low recall is easy
Combined measure F_1 and F_ß
- p and r in signle metric, harmonic mean between p and r
-
-
- mit ß < 1 Fokus auf precision, ß > 1 recall, ß = 1 balanced
- je nach usecase will man anders gewichten
Accuracy

Ranked Evaluation
- Problem: es ist nicht so einfach zu sagen welches IR System im vergleich zueinander besser ist… dafür brauchen wir relevanz Einschätzungen, diese sind aufwending herzustellen
- Motivation: Nutzer schauen sich oft nur die top query Ergebnisse an → ergo ist das ranking essentiell wichtig für die Güte eines IR Systems → recall,precision,F schauen sich allerdings nicht den rank an
- Idee: turn set measure into measures of ranked list

- zB p@3 wie viele von den ersten 3 Ergebnissen waren relevant (2/3 = 0,66)
- Für jede dieser sets kann man die percision and recal werden plotten um eine kurve zu erhalten
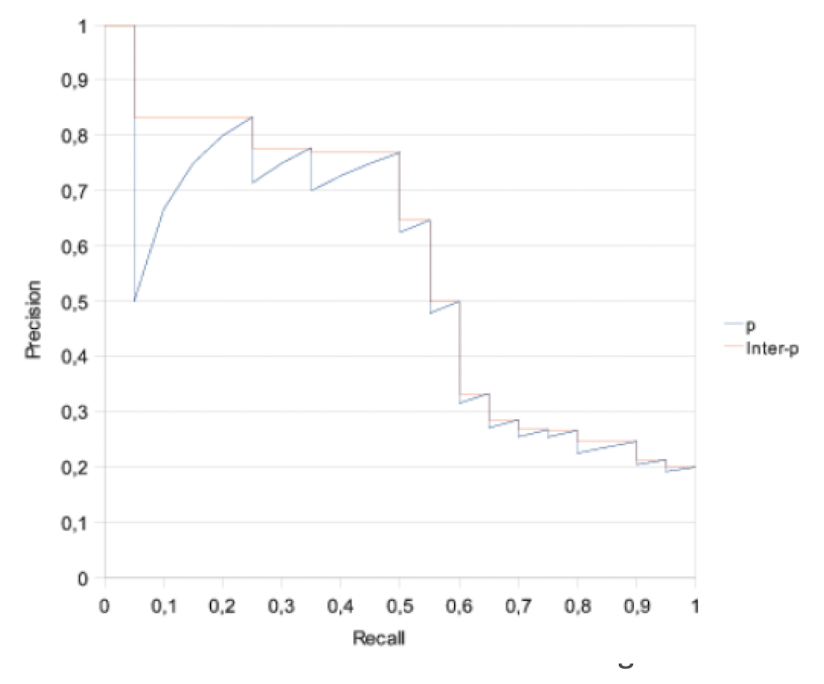
11-Point Interpolated Average Position
- Idee: single number Repräsentation
- Arithmetisches mittel der interpolierten 11 Punkte (0.0, 0.1, 0.2 … 1,0) der recall kurve
Mean Average Position (MAP)
- “wie vorher nur über mehrere queries”
- die durchschnittliche Fläche unter der pr-rec-curve für eine Menge von queries


Evaluation Benchmarks
- Motivation: müssen ir systeme vergleichen, was sind gute systeme?
- Optionen
- User experiments (teuer, realsitisch, nutzer finden, wie observieren)
- typischerweise pensionierte bibliothekare (bias)
- Test Collection (billig, fits person to machine)
- erlaubt wiederhobarkeit
- User experiments (teuer, realsitisch, nutzer finden, wie observieren)
Pooling
- Menge von Dokumenten und menge von queries die wir haben und x IR Systeme, fragen die Systeme, und die top 5 des jeweilgen systems in einen Pool → das dann bewerten lassen
Validity of Relevance Assessments
- Kappa measure hilft dabei relevanz maße von zwei juroren einzuschätzen wie oft diese übereinstimmen
- Statistisch gesehen bestimmen, das nicht durch zufall ähnliche Entscheidungen getroffen werden
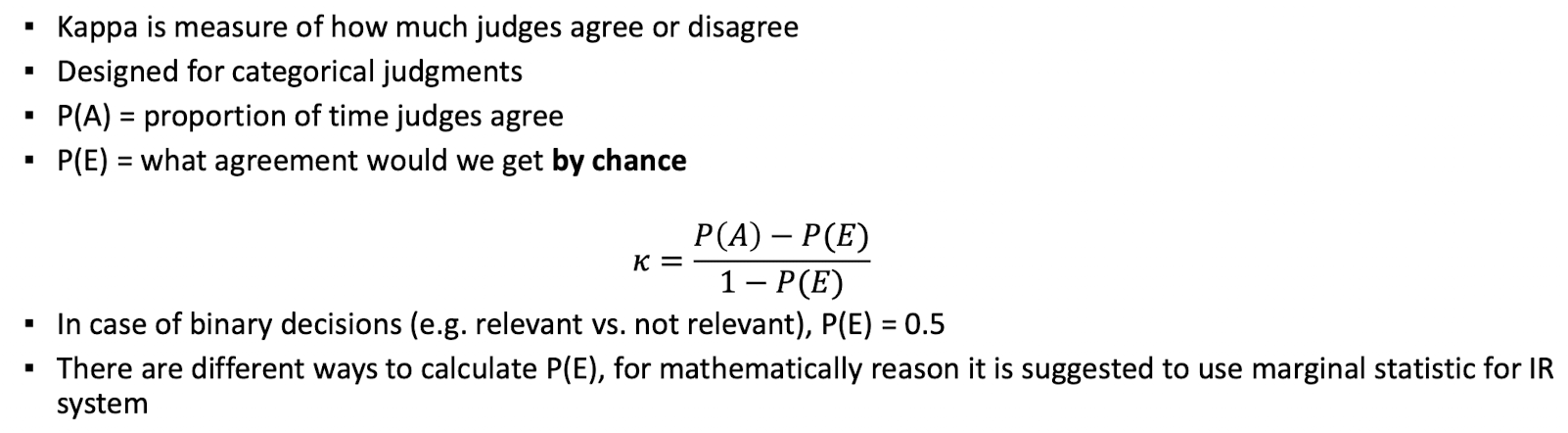
Query Logs
- Logging zu welcher query was geklickt wurde
- korreliert mit relevanz, hat aber auch noise
- Wie oft wurde dokument in pos geklick abzüglich normaler klick rate für diese position
Result Summaries
- Motivation: Nutzer will nicht jedes dokument anschauen um seine info zu bekommen
- Ziel: die Ergebnissliste so informativ machen, dass der Nutzer finales ranking selbst macht
- meist durch Titel, url, metadaten und kurz-Beschreibung
- 2 basic kinds
- static - unabhänig von query
- meist subset des Dokumenten Inhalts
- erste 50 wörter oder besser key Sätze des Dokuments
- dynamic - passt sich der query an
- innerhalb des Dokuments snipped suchen welches zu query passt
- Ergebniss sollte nicht zu lang aber auch nicht zu kurz sein
- erhöht die User happiness
- static - unabhänig von query
Block II: Relevance Feedback and Query Expansion
- Motivation: automatisiert query verändern, oder Vorschläge anzeigen, meintest du vielleicht xyz
Motivation
- Informationen können durch verschiedene Wörter ausgedrückt werden
- Ziel: ein gutes IR zeigt auch Dokumente mit airplane an wenn man zB nach aircraft sucht
- also Recall erhöhen
- Zwei wege
- Relevance Feedback - local on demand analysis for a user query
- Query expansion - global analysis over whole collection to produce a thesaurus
Relevance Feedback: Basics
- Idee: es ist schwierig eine gute Anfrage zu schreiben wenn man die Collection nicht kennt, Lösung: iterieren
- Nutzer kann stück für stück die Anfrage refinen durch auswählen was er relevant findet
- “ähnliche Seiten in Google”
Relevance Feedback: Details
Konzepte von relevanz Feedback
- Centroid
- ist das Zetrum der Masse für eine Menge von Punkten
- wir können centroid von Dokumenten berechnen
Rocchio Algorithm
- Idee: finde einen query vector welche die similary mit relevanten dokumente maximiert und minimieren der similarity von nicht relevanten dokumenten
- Verschieden der centroidien der relevanten um die differenz der relevanten zu den nicht relevanten
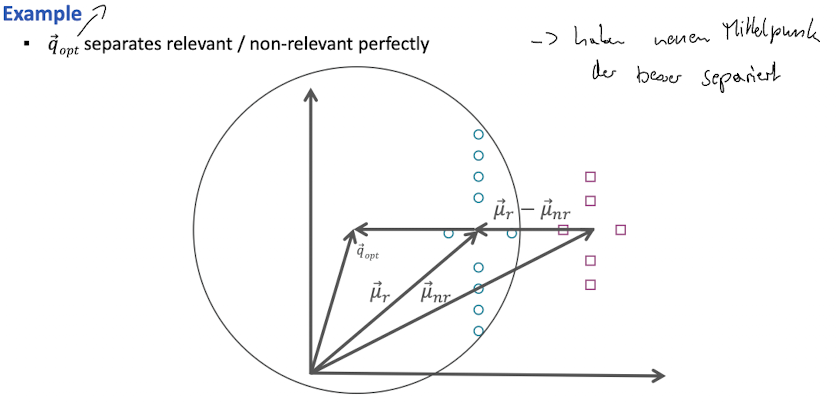
- Rocchio 1971 SMART
- wie normal nur mit Gewichten; je nach IR System unterschiedlich
- Annahmen:
- Menschen sind in der Lage initiale Suchanfrage durchführen zu können
- Menge von relevanten sind homogen
- Evaluation
- two oder mehr runden marginal sinnvoll
- mindestens 5 documente sind empfolen
- Caveat
- alternattive zur elvance feedback: user revises und query resubmission
- gibt keinen beweis das relevance feedback is “best use” of users time
Relevance Feedback on the web
- wird nicht so oft eingesetzt, maximal bisschen im Hintergrund
- Nutzer sehen es nicht ein die arbeit der suchmaschine abzunehmen
- wollen ergebniss in einer interaktion
- Dokumente sind so viele mittlerweile das man zu nischigen suchbegriffen trotzdem was findet, egal ob “airplane” oder “aircraft”
Pseudo-Relevance Feedback
- Idee: nehmen die top n Ergebnisse, dann Mittelpunkt → diesen für relevanz feedback benutzen
- geht meistens, aber
- can query dift verursachen
Indirect Relevance Feedback
- Idee: nutzer nicht direkt fragen, sondern clicks nehmen als implicites Feedback
- dazu sollte die Zusammenfassung der Website sehr gut sein, sonst könnte es sein das die Nutzer nicht drauf klicken wegen der Zusammenfassung (nicht gut formuliert) nicht weil es relevant sind
Query Expansion
Idee: wie können wir mit dem globalen wissen unsere Suchanfragen verbessern
- eine Methode um den Recall zu erhöhen
- Informationen die wir brauchen sind (near-) synonym - nennt man thesaurus
- Types of user feedback
- feedback on documents → more common in relevance feedback
- feedback on words or phrases → more common in query expansion
- Types of query expansion
- manual thesaurus (maintained by editors e.g. PubMed)
- automatically derived thesaurus (based on co-occurence statisitics)
- query equiuvalence (based on query logs)
Thesaurus-based query expansion
- wir erweitern für jeden term t die query mit semantisch ähnlichen
- recall erhöhen
- zB “hospital” → “hospital medical”
- wird vermutlich precision verkleinern
- wird in experten suchmaschinen verwendet, sonst zu aufwendig den thesaurus zu kuratieren
- recall erhöhen
- Automatic Thesaurus Generation
- Idee: durch die analyse der verteilung der Wörter automatisch aufbauen
- Definitionen
- wenn Wörter zusammen vorkommen
- “car” wie “motocyle” wegen “road”, “gas”, “licence”
- wenn Wörter in bestimmten grammatischen beziehungen mit gleichen Wörtern auftauchen
- you can harvest, peel, eat, prepare apples and pears → apples and pears ähnlich
- wenn Wörter zusammen vorkommen
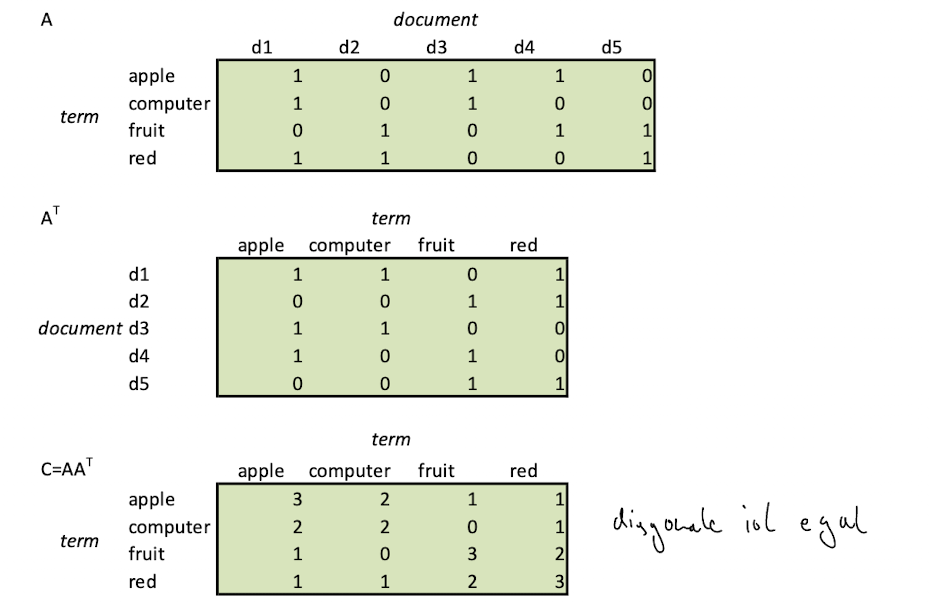
- Building a co occurence based thesaurus
- term document Matrix A aufbauen
- dann C berechnen C = AA^T
- C ist die anzahl wie oft terme co-occuren (umso höher umso besser)
Query Expansion at Search Engines
- Hauptquelle für query expansion sind die query logs
Block 3: Vector Space Text classification
Overview of Document Classification
Ziel: Dinge in Kategorien einteilen.
- Dokument werfen wir in Klassifikator rein (Blackbox) der weist dann Kategorien zu
- Kategorien werden vorher festgelegt
- Kategorien, haben unterschiedlich viele Elemente
- Kategorien können auch hierarchisch organisiert werden
- Dokumente: texte, html, json, Bilder
- typisch: Spamfilter, Sentiment Analysis, Routing, Filtering, postive vs negative review
- Ablauf
- Training mit gelabelten Daten
- Modell ist nur so gut wie Trainingsdaten
- Überlappend auch möglich, wenn man jeden individuell fragt zu klassifizieren
Evaluation
- Wie kann man die Qualität messen?
- neben dem Trainingsset auch ein testset nutzen, um label mit den vorhersagen zu vergleichen
Category specific classes
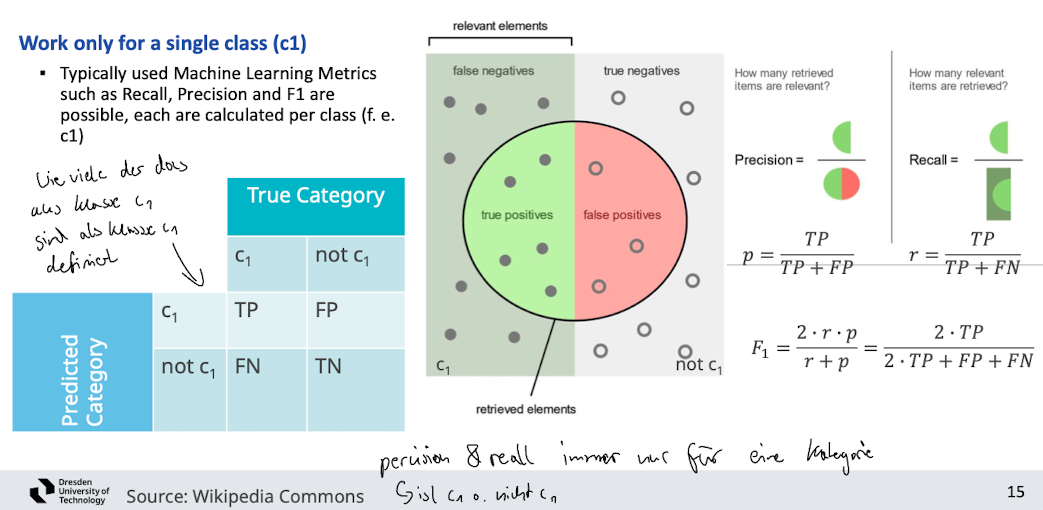
- was aber wenn wir mehrere Klassen haben? wie bewerten
- könnten precision und recall für jede Klasse individuell berechen
- oder Accuracy und Error Rate anschauen
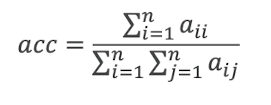
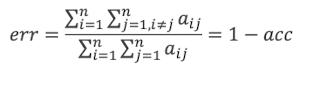
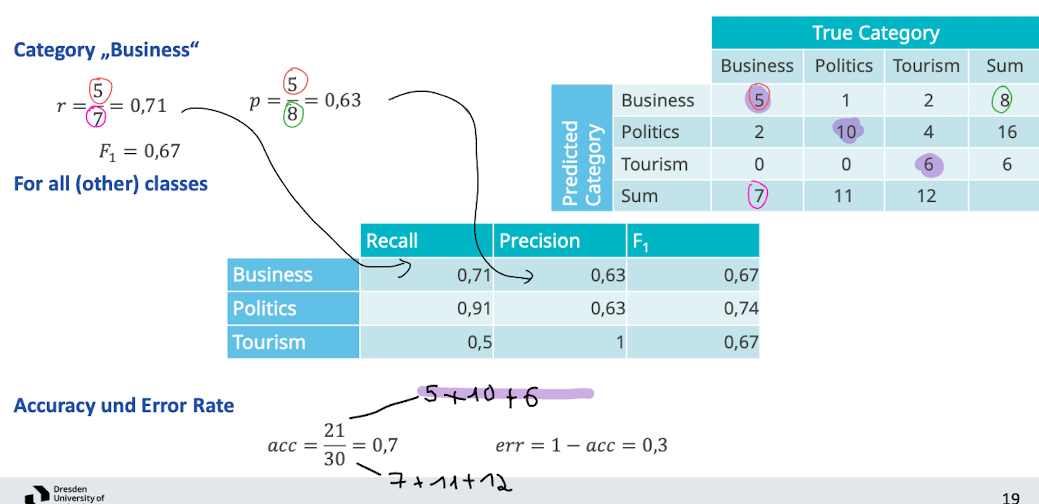
- Kritik an Accuracy
- sehr große Kategorien können die Genauigkeit der Metrik verzerren
Train-Test-Split
- Train-Set: wird für training verwendet
- Test-Set: wird nicht für training verwendet, sondern um zu überprüfen wie gut das model auf anderen Daten funktioniert
- Train-Test-Split: je nachdem gibt es einen 50/50 oder 70/30 Aufteilung
k-fold Cross Validation
- Motivation: Bias durch das test set vermeiden
- Idee: datensatz in k gleich große buckets aufteilen; k mal bucket i als trainings daten; k modelle; am Ende durchschnittliche Ergebnisse pro split
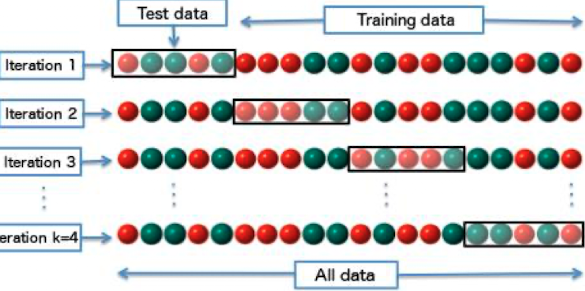
Classification in Vector Space
- Approaches for Text Classification
- Neural Network
- Naive Bayes
- SVM
- Vector Space
- Distance in Vector Space
- Recap: Documente können wir im Vektorraum darstellen (tf-idf vektor)
- Distance
- Euclidean Distance
- Standisieren auf länge = 1
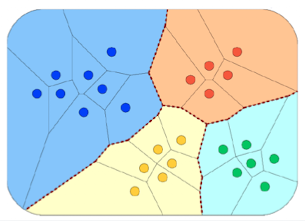
Rocchio Method
Rocchio
- Note: Related to relevance feedback method
- Annahmen
- Dokumenten Vektoren einer Kategorie sind typischerweise nah beeinander positioniert und weit weg von anderen kategorien
- Training
- Im Training die Mittelpunkte der Kategoriern anschauen / Schwerpunk → centroide
- den Mittelpunkt merken wir uns → steht repräsentativ für die Kategorie
- Anwenden (classification task)
- unbekannter Vektor kommt hinzu
- schauen, wie nah der Vektor zu den centroiden ist
- geringste Distanz bestimmt dann die Klasse
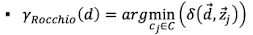
- Cool: wie müssen uns die ursprünglichen Dokumente nicht merken

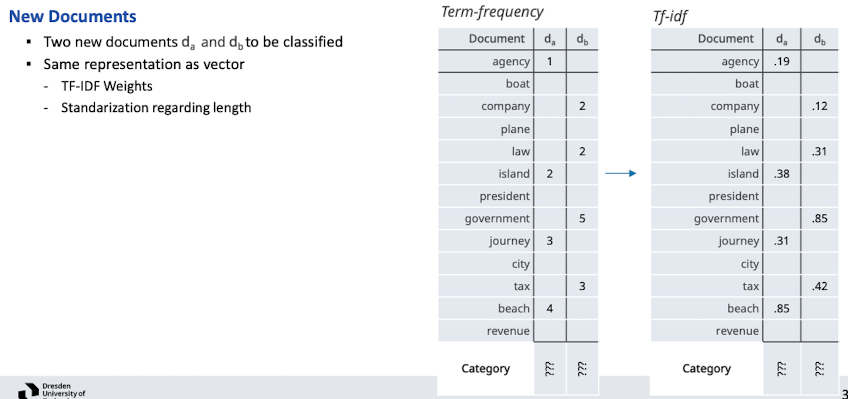

Limitations der Klassifizierung
- klare Trennung kann manchmal nicht gefunden werden
- spezielle formen, nicht homogenes kann nicht getrennt werden
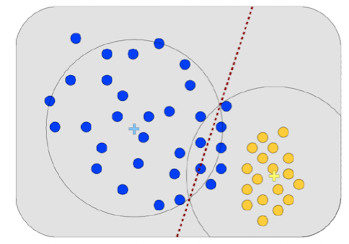
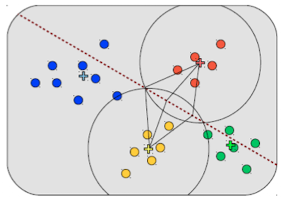
K Nearest Neighbor (KNN)
- K ist ein Parameter (solte nicht gerade
- gibt hier kein direkten Trainingsprozess, merken uns alle trainingsdaten
- kommt ein neuer Punkt schauen wir und die k nächsten Nachbarn an und nutzen diese Kategorien
- Vorteil: kein Training notwendig
- Nachteil: bei vielen Daten aufwendig

- traadeof zu nächsten nachbarn und weiteren Einträgen
- wir haben wieder gerade Linien zum trennen, aber mehr als vorher
- beachte
- ungerade werte bevorzugen um tie zu avoiden
- k=1 ist prone to outliers
- wir müssen nichts trainieren, sind also unabhänig wie der raum aufgebaut ist
Block 3: Statistical Language Models
Introduction
- (statistical) Language Model ist ein Ansatz um die Generierung von Text zu beschreiben
- Buchstaben bekommen auftritts-wahrscheinlichkeiten zugewiesen
- innerhalb eines Dokuments wie hoch ist die Wahrscheinlichkeit das nach einem Wort das nächste Wort auftaucht
- Application
- sprache erkennung
- Part of Speech Tagger
- Handwritten text erkennung
Principle
- Finite Automaton (FA)
- Wörter in einem Graphen
- Übergangswahrscheinlichkieten
- Zustände
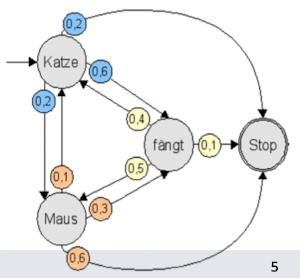
- Annahme: jedes dokument wurde von einem FA generiert
- Model (unigram sprach model)
- Wörter, aktueller Zustand, Wahrscheinlichkeiten
- Wahrscheinlichkeiten unabhänig (wieder bag of words) / kein kontext
Instance Model
- jedes Dokument generiert ein Wahrscheinlichkeitsmodell
- also Multiple Modelle M1, M2, … Mk
- Welches Modell matched der instance
- Beispiel
- Eintrag “Dogs catch cats”
- Zwei Modelle


- Welches Wahrscheinlichkeitsmodell passt besser zu einem Zustand
- beide Low
More Complex Models
- man sieht es gibt keine Satzzusammenhänge, man verliert den Kontext
- P(dogs, catch, cats) = P(cats, dog, catch) ???
- zu schwach für viel Applikationen
- Alternative:

- Lösung: Limit the considered horizon (”abschneiden”, sliding window das man durchschiebt)

- Horizont
- Alternative Interpretation: Wahrscheinlichkeiten von zwei folgenden Wörtern → Trigramme
- kein Horizont ⇒ n=0 → unigramm
- n=1 → bigram – n=2 → trigramm… (zwei vorgänger und aktuelles)
- Alternative Interpretation: Wahrscheinlichkeiten von zwei folgenden Wörtern → Trigramme
Use of Probalistic Language Models in IR
- Idee: wie hoch ist die Wahrscheinlichkeit für ein bestimmtes Dokument unter der wahrscheinlcihkeit das ich eine bestimmte query → wie gut passst das dokument; wie wahrscheinlich generiert die query das dokument
- ausrechnen und absteigend sortieren → ranking
- P(d | q)
- Transformation der Wahrscheinlichkeit via Bayes’ law
- “für jedes Dokument, Modell generieren und dann schauen, mit welcher Wahrscheinlichkeit generierst du meine query” → easy
- p(q) easy → konstant
- p(d) easy → konstant (jedes dokument sollte gleiche chance haben)
- könnte aber auch zB neue dokumente priorisiern zB wenn neu


- Also können wir die ca. gleichsetzten

Multinomial Distribution
Anderer Ansatz, da einfacher zu berechnen
- Anfrage is das ziehen von Bällen mit zurücklegen

Unigram LM

Assment of Probabilities
- Motivation: wie kommen wir für einen term für ein dokument zu der wahrscheinlichkeit

- Idee: wir schätzen das ab MLE

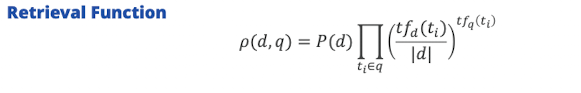

- Idee: wenn ein term nicht im dokument vorkommt (lokal), dann ersetzt mit der wahrscheinlichkeit des terms über ganze korpus (global)

Jelinnek-Mercer Smoothing
- ein Parameter der smoothed von wie viel häufigkeiten aus dokument und wie viel aus global/korpus

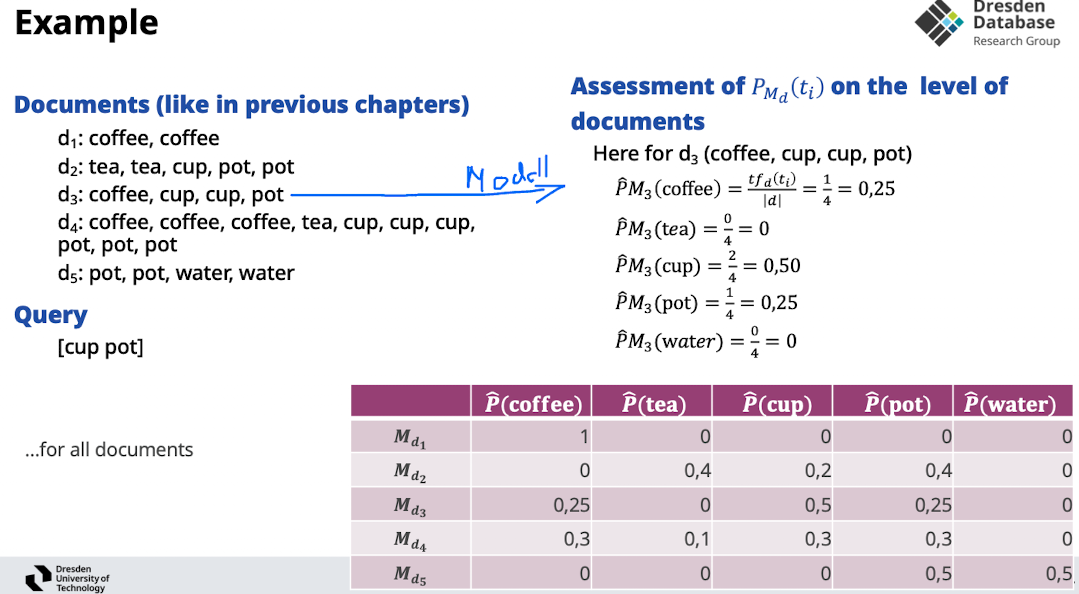
- retrival:
- jetzt auf Kopri Ebene


Practical Implementation
- anstatt die sehr kleinen zahlen zu mulitplizieren, lieber log der zahlen und dann summieren
- Term-at-a-time
- durch smoothing hat jedes doc ja eine wahrscheinlichkeit
- überlicherweise Simplifizierung: nur dokumente die mindestens 1 query term haben anschauen

Comparison Vector Model
LMs vs Vector-Space-Model
- Ähnlichkeiten
- term frequenzen
- wahrscheinlichkeiten sind normalisiert (summiert sich auf 1)
- mix aus lokalen und globalen Gewichten
- Annahmen: Bag of words
- Unterschiede
- term frequenzen und legth normalisierung unterschiedlich angewandt
- Vector-space-model: based on geometrical similarities vs. founded mathematical probabilities
Block 3: Neural Networks
Supervised and Unsupervised Learning
- supervised
- infer a function from labeled data
- cost function sagt mismatch zwischen data und label
- regression, forecasting, classification
- unsupervised
- description of hidden structure in unlabeled data
- minimizing the cost function comparing x with output f
- clustering, association rule mining, anomaly detection
Neural Networks
Sentiment Analysis

General Idea
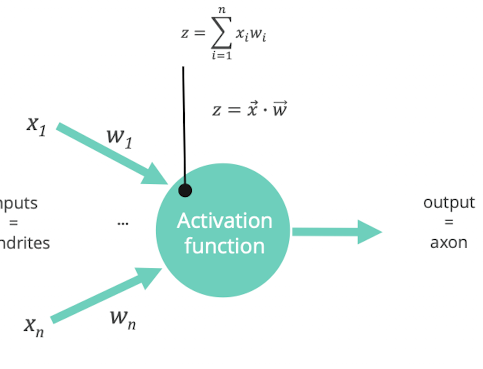
- Perceptron:
- kleinste Einheit
- Beispiel: als Eingang alle Wörter der engl. Sprache, alle Wörter der Eingabe gewicht von 1
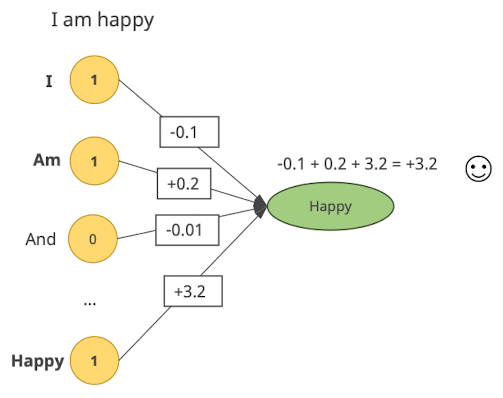
- Neural Network
- jetzt mehrere Neuronen jedes hat unterschiedlichen Fokus
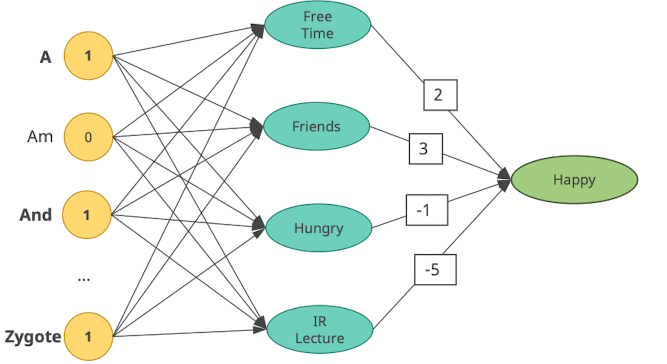
- kann dann beliebig noch Ebenen einführen
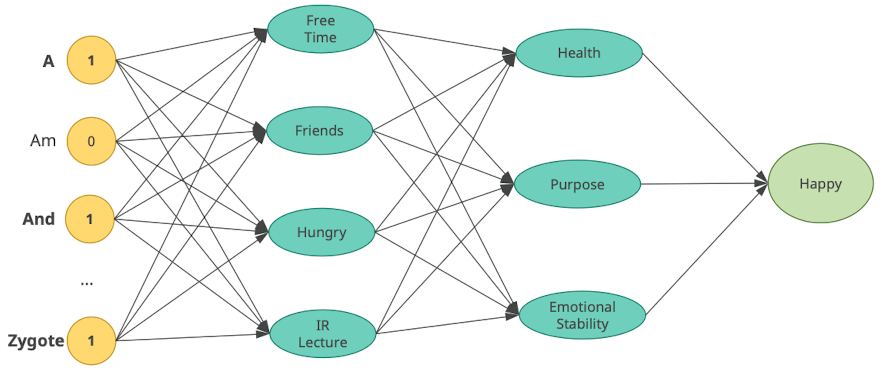
- Deep Neural Network
- da wissen wir nicht was die Neuronen als kriterien haben
- wir erlernen das
- jetzt mehrere Neuronen jedes hat unterschiedlichen Fokus
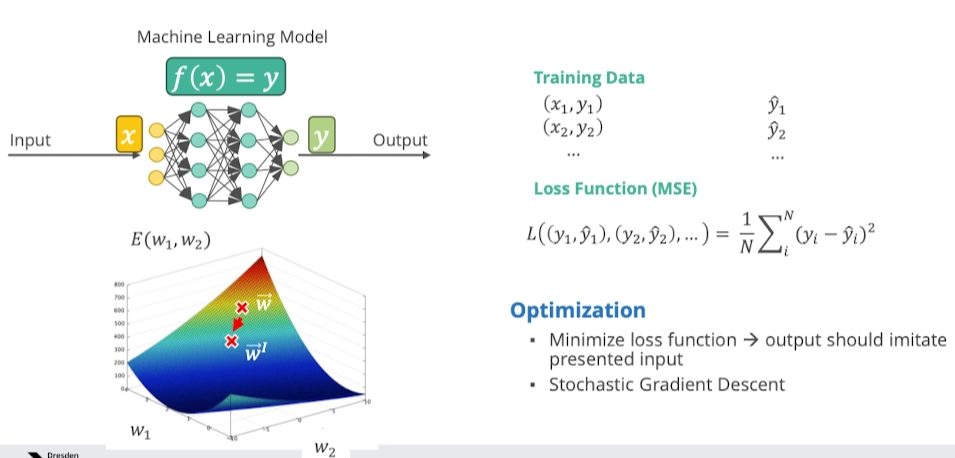
Training - Optimization
Basics
- Single Neuron
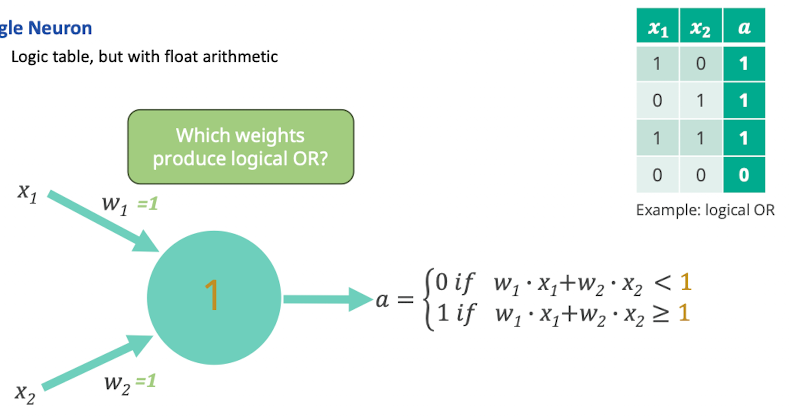
- wenn gewichtete Summe > 1 dann 1 als Ausgabe sonst 0 als Ausgabe
- um OR funktionalität sich anzuschauen dann müssten die Gewichte zB jeweils 1 sein
- Perceptron (zwei eingabe + 1 output)
- Neuronen generell
- kann man sich als Aktivierungsfunktion vorstellen
- ab wann ist das neuron aktiv
- Trainingsalgorithmus
- zufällige Gewichte → schauen wir falsch wir sind → rückwärts schauen wo informationen reinfließen, wollen wir größere bahnen bauen
- gewichte verändern und erneut machen
- Brauchen eine Gewichtsveränderung
- diff w = learning rate * input_i * output_j (nur wo information eingehen und weiterfließt, größer bauen)


- diff w = learning rate * input_i * output_j (nur wo information eingehen und weiterfließt, größer bauen)
- kann man sich als Aktivierungsfunktion vorstellen
- Anwendungsfall Punkte linear seperiern
- mit nur ein Neuron ist XOR nicht trennbar
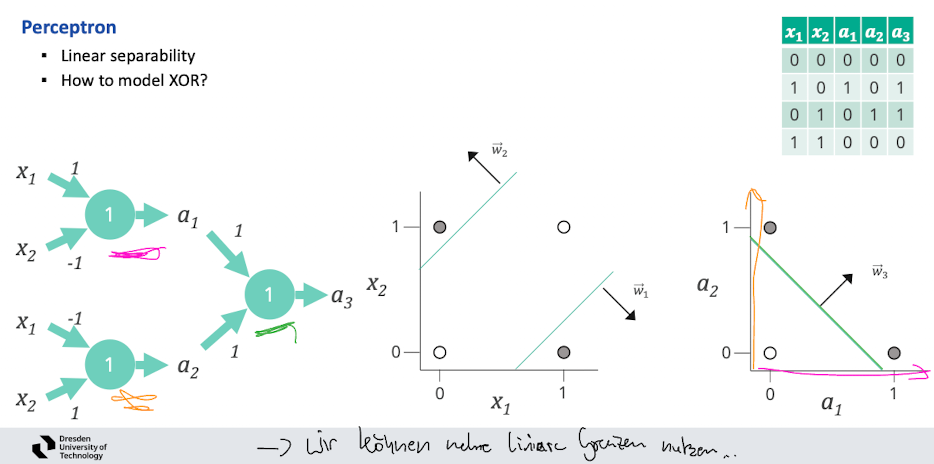
- Multilayer Perceptron
- namen: Input Schicht, Hidden Layer, Output Layer
- gibt beliebige Möglichkeiten wie Neuronen verbunden sind
- Limits
- All or nothing (neuron feuert oder nicht, Aktivierungsfunktion)
- fine tuning nicht möglich
- weight updates teilweise keinen impact (und dann plötzlich bei flip)
- wir wollen
- small change in weights → small change in output
Training Neural Networks: Backpropagation, Stochastic Gradient Descent
Another activation function
- Sigmoid Neuron
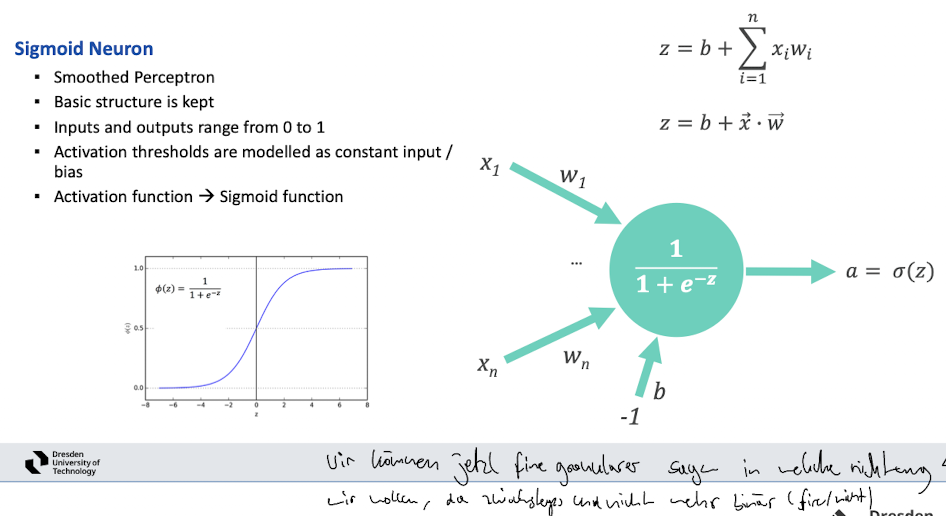
Training: Optimierungsproblem
- Algorithmus zum lernen
- Ziel: minimaler Abstand von wanted und actual output
- dazu weights anpassen
- Optimierung pro vector → multi dimensional, nicht linear…
- Ziel: minimaler Abstand von wanted und actual output
Gradient Descent
- random w Vektor
- slope berechnen (ableitung)
- zeigt immer dahin wo das minimum ist
- je näher wir uns dem minimum nähern, desto flacher wird der winkel
- gibt uns Richtung und wie weit wir noch bis zum minimum müssen
- Probleme
- slope to large → overshoot kann passieren
- Lösung: slopes kleiner machem, mit learning rate param (dynamisch je nach wie weit im training)
- local minimal → wollen ja globales…
- Lösung: von verschiedenen startpunkten starten, viele gradienten, sollten globales finden
- slopes too small → training sehr langsam, stuck in local minima
- Lösung: größere learning rate
- slope to large → overshoot kann passieren
- zusammenfassend
- minimieren der cost function
- gradient der cost function gibt richtung des größten abstiegs
Training Optimization: Gradient Descent
- nutzen von alpha als lern rate
- step by step adjustment
- gradient hilft die neuen Gewcihte zu errechenen

- aber:

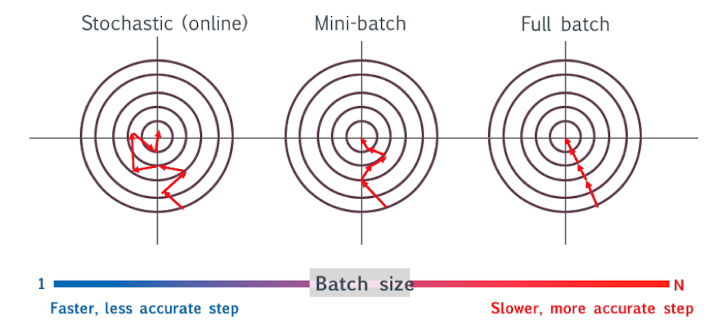
Stochastic Gradient Descent
- als approxierung

Mini Batch Gradient Descent
- …noch besser - batchweise Trainingsdaten nehmen um zu optimieren pro Schritt

Traning: Variants of Gradients
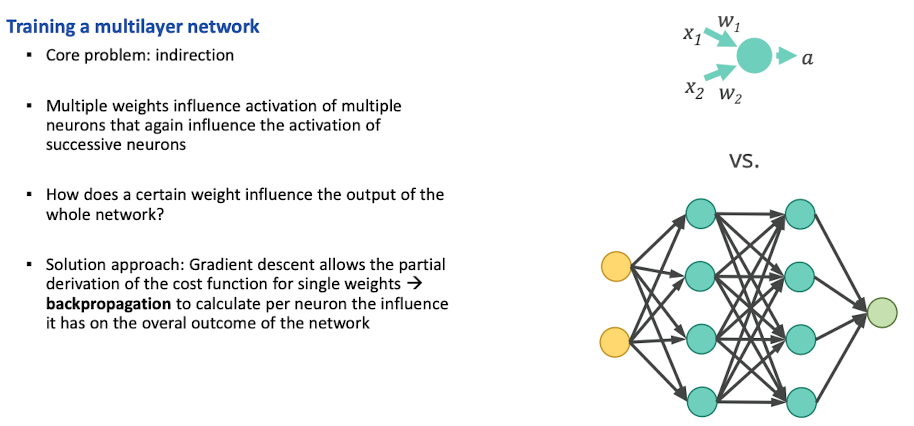
Backpropagation
Fehler wird am ende berechnet, durch das ganze Netzwerk durchgesteckt, Mathmatik hat das ganze gelöst für uns
Variants of Neural Networks

- Wann nimmt man was?
- es kommt auf den Use case drauf an → am besten einfach probieren
Traning: Problems
- Overfitting
- mit genug parametern kann alles gemodelt werden
- heißt aber nicht ist gut → failen zu generalisieren
- Netzwerk ist zu angepasst an die Lösung
- Regularization
- L2 regularization als weight decay (gibt auch L1)
- add penalty to cost function
- → favors small weights
- Dropout
- beliebteste method um overfitting zu vermeiden
- in jeder trainingsiteration einige neuronen droppen
- input / output ist für diese ignoriert
- → neztwerk lernt allgemeiner und sich nicht auf einzelne neuronen zu verlassen
Parameter
Block 3: Word Embeddings
Sparse vs. Dense Embeddings
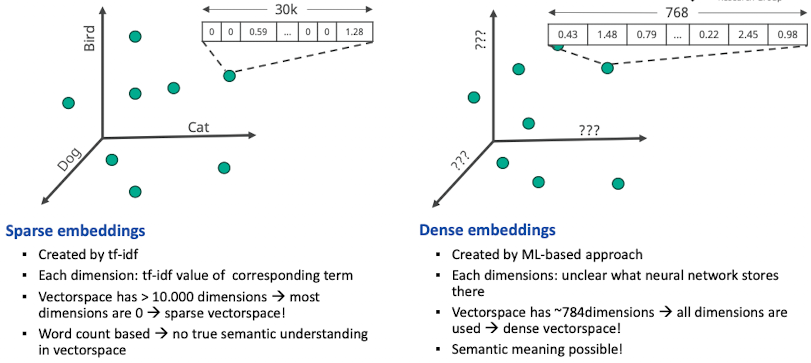
- ab jetzt schauen wir uns dense Embeddings an
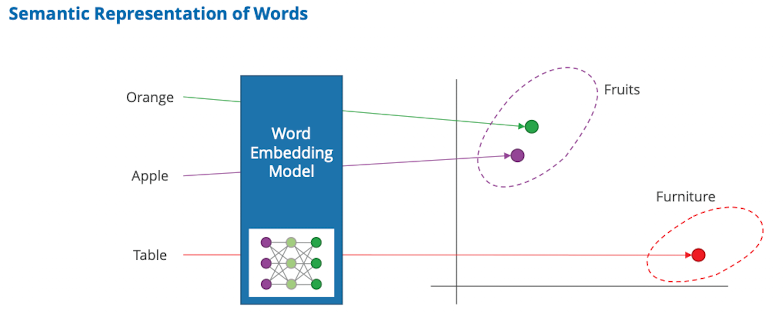
Word Embeddings
Motivation: Machine Learning geht nur mit zahlen, input für neuronale netzwerke muss numerisch sein
- Random allocation
- Idee: random wörter zahlen geben
- Problem: netzwerk ist verwirrt weil ähnliche zahlen nicht ähnliche inhalte
- Problem: wir wollen ähnlichen wörtern ähnliche zahlen geben → schwierig
- Ziel:
Word2Vec
…ein Model welches das kann
- Idee: Wörter stehen nicht alleine, sondern im kontext eines Satzes → Kontext beschreibt was das Wort bedeutet
- wenn wir nur Kontext sehen und das Wort fehlt, können wir trd das Wort erraten
- Wir lassen das ein Netzwerk machen
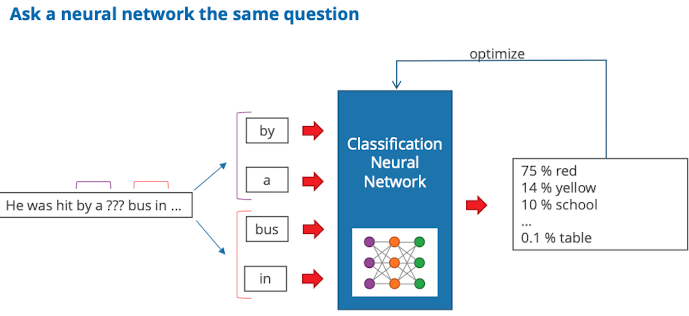
- um die Aufgabe zu lösen muss das Netzwerk verstehen, was die Sprach auf bedeutungsebene bedeutet
- Trainingsdaten sind sehr einfach zu erstellen
- Wie effizient berechnen?
- paar Wörter vor und nach Ziel nehmen, classsification Algorithmus trainieren ein Wort auszuwählen (auf public data, zB wikipedia)
- Wie sieht das im NN aus?
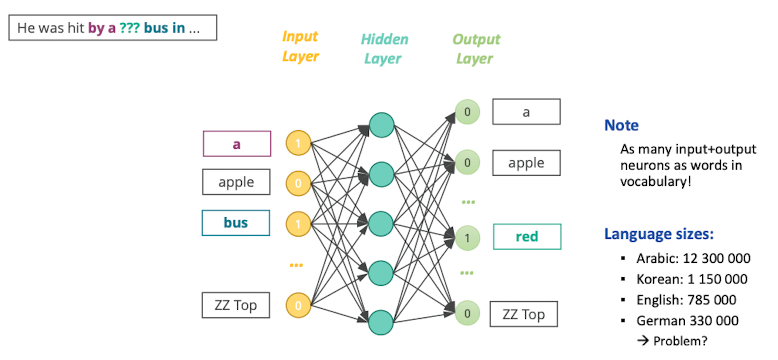
- Aus den ganz vielen Wörtern sind nur ein paar aktiv, die Gewichte ausgehend von “bus” sind die Embeddings von bus etc.
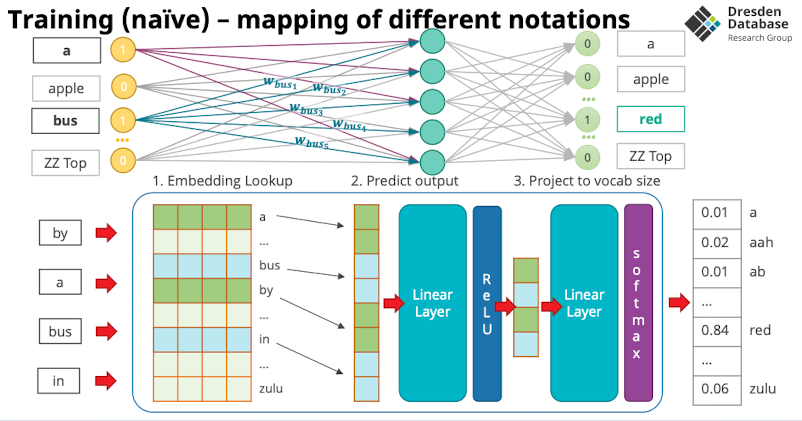
- Warum Matrix ne gute Idee: GPUs sind gut in matrix Multiplikation
- Dann wird folgendes sehr effizient aus dem speicher holen
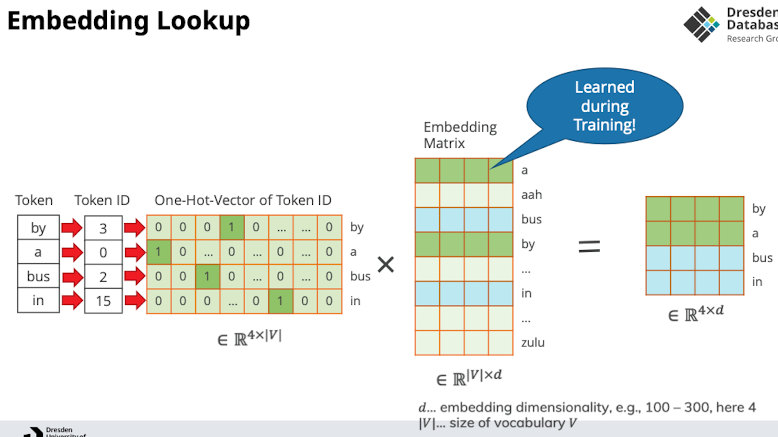
- Jetzt komplette Klassifizierung
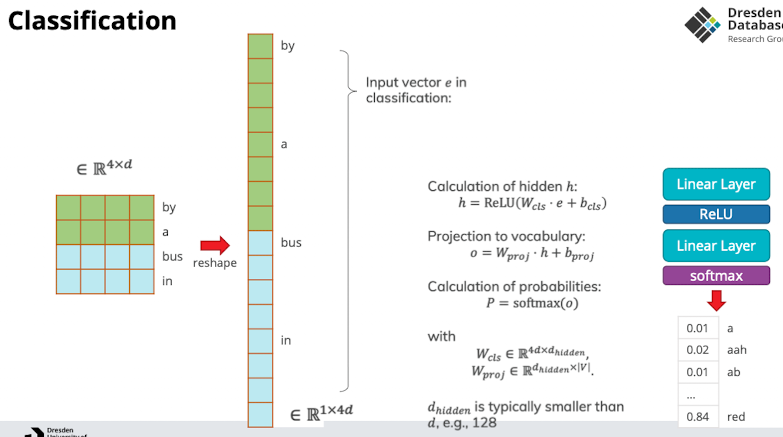
- Zusammengefasst
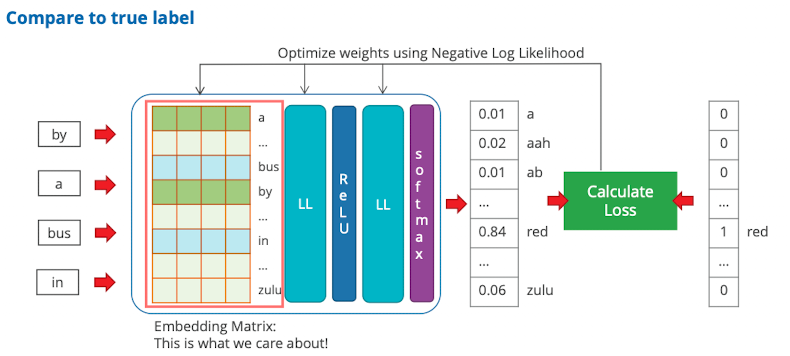
- Wir haben jetzt eingabe Layer auf 4 reduziert aber der Output ist immernoch das ganze vocab → für jedes müssen wir softmax machen
- Lösung: wir fragen nicht mehr was ist das fehlende Wort, sondern welche Wörter erscheinen zusammen
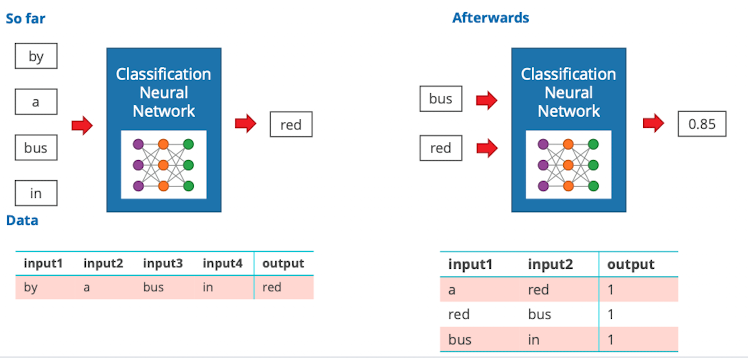
- Achtung: hat von haus aus einen Accuarcy von 100%
- um das zu vermeiden negative Samples mit ins training set reinbauen
- zufällige Wörter die keine Nachbarn sind
- so können wir es zwingen es wirklich zu verstehen
- Lösung: wir fragen nicht mehr was ist das fehlende Wort, sondern welche Wörter erscheinen zusammen
Zwei varianten
- Continuous bag of words (CBOW)
- schnell, skaliert aber gut
- predict word from context
- Skipgram
- predict context words from word
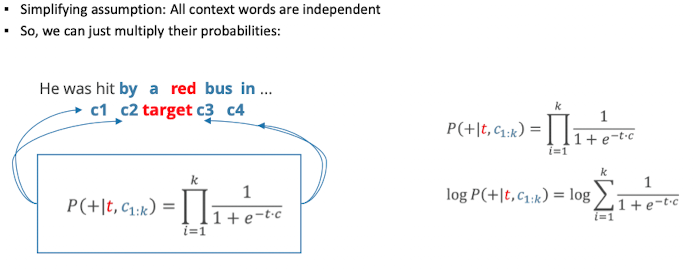
Skipgram
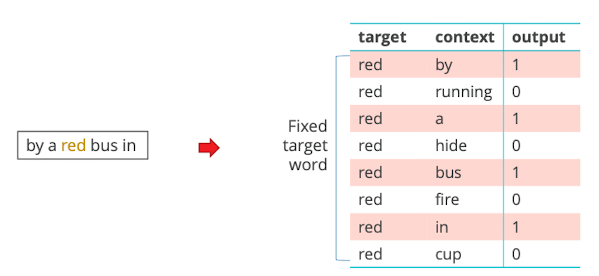
- Ablauf
- pro Wort alle context wörter und negative aufschreiben
- mit neural netwirk classifier trainieren um die 2 cases zu sehen
- use weights as embeddings
- Training sentence with context window: c1 c2 target c3 c4
- wollen die wahrscheinlichkeit für c ist Kontext
- similarity mit dot-product
- dann mit sigmoid funktion als wert zwischen 0 und 1

Applications
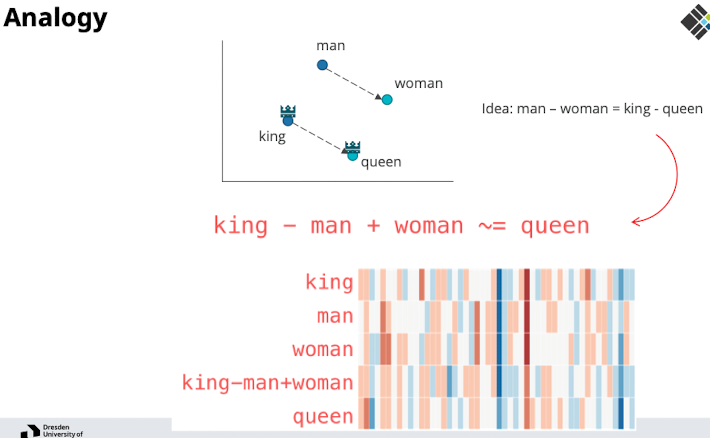
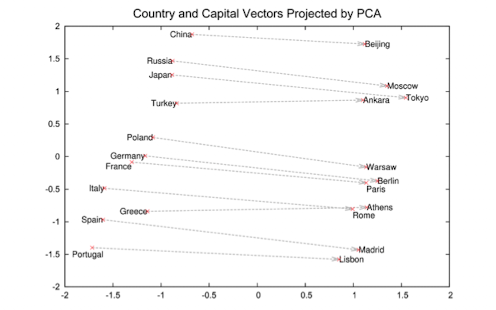
- Applications
- IR
- Text understanding
- Classification
- Part-of-Speech Tagging
- Named-Entity-Recognition
Applications for Informations Retrieval
- Query Expansion using Word Embeddings
- actung: query drift

- Translation
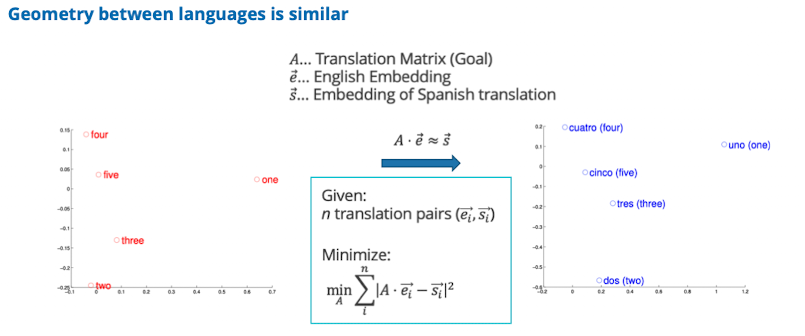
- Cross-Lingual Retrieval


Block 3: Attention, Transformer Architecture, BERT
Wieder word Embeddings aber nun mit context
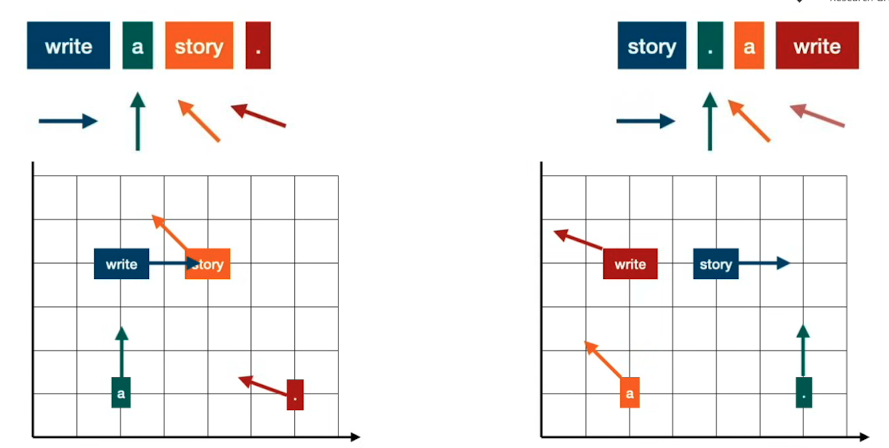
Attension Mechanism
Attension = Embedding verändert sich durch der umliegenden Wörter
Multi Heade Attension = Attension in verschiedenen Vektorräumen ermitteln → schauen wo am besten klappt
Context-free Embeddings vs Context-aware Embeddings
Andere Wörter verschieben das Embedding in die richtung wo die Wörter liegen
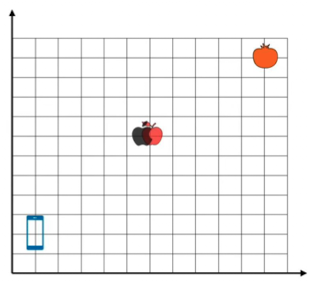
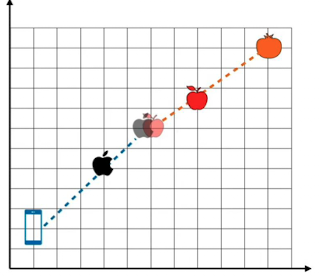
Attension as gravity
Attension kann man sich als Gravitation vorstellen realisiert durch feststellen der similarity
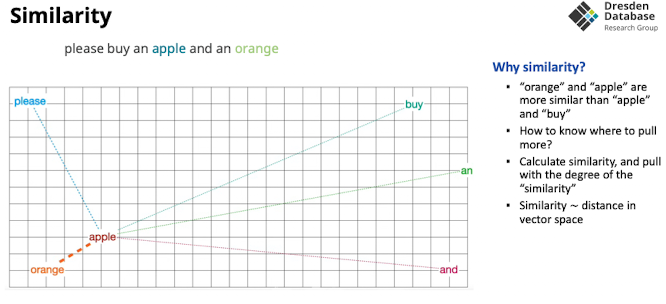
- Wie messen wir die Ähnlichkeit?
- Cosine Similary (Winkeln anschauen)
- → als alternative Dot product, da alles längennormlisiert
- Dot Product
- normales Dot produkt
- → als alternative Scaled Dot Product, dadurch werden die Produkte nicht so groß
- Scaled Dot Product
- Dot product + teilen durch die Anzahl der Dimensionen
- Cosine Similary (Winkeln anschauen)
Similarity Beispiel
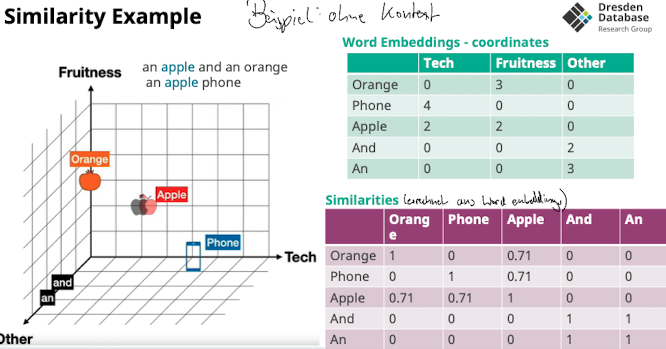
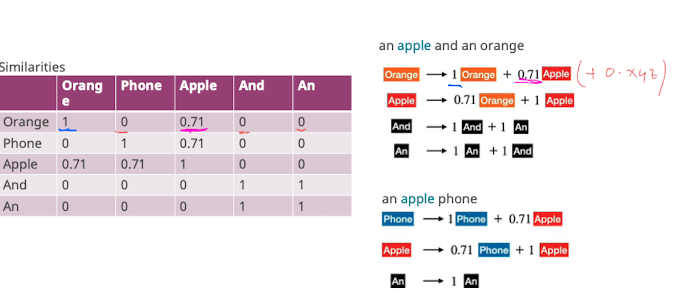
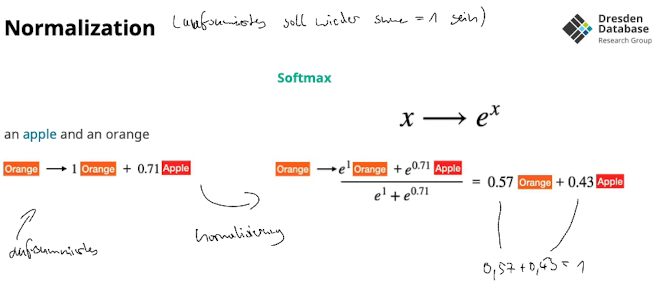
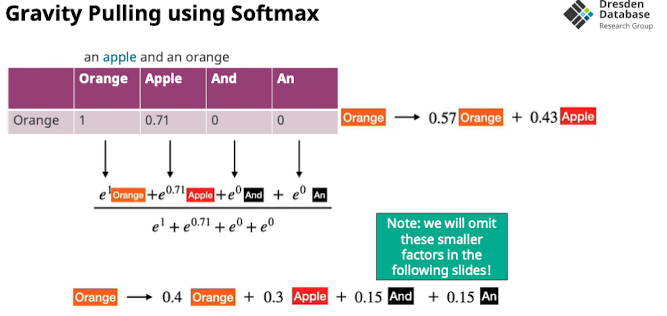
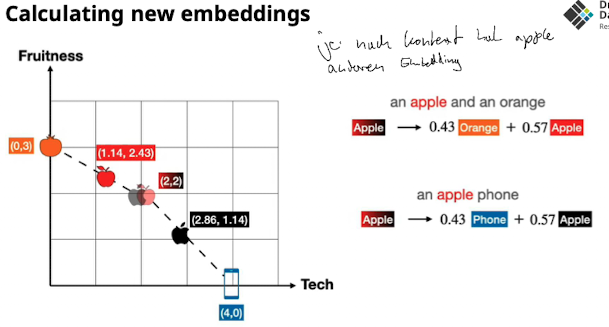
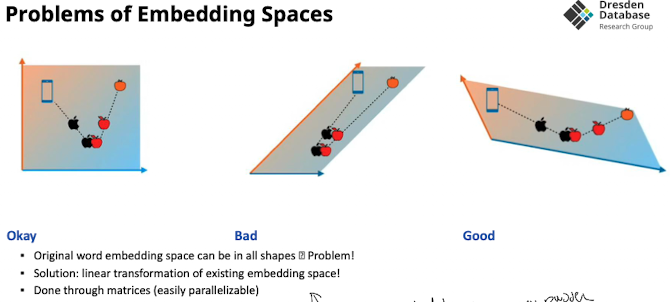
- Damit und das gravity pulling hilft müssen die RIchungen möglichst divers sein (siehe Problems slide) → “möglichst großer winkel”
- Lösung um das zu forcen:
- mehrere Vektorräume nutzen sodass embedding möglichst du funktioniert
- Lösung um das zu forcen:
Linear Transformation using Key and Query Matrix
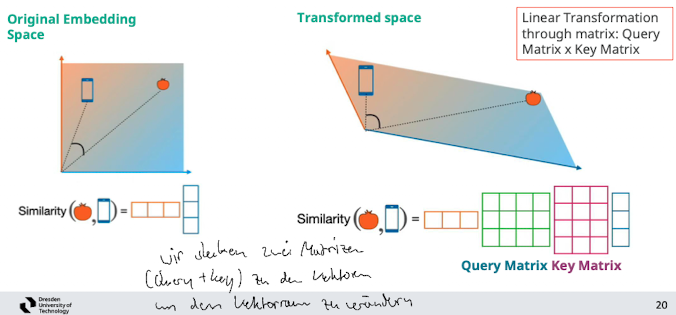
→ mit mehreren Query & Keys zwischen die beiden Matrizen den Raum transformiern durch lineare transfomieren
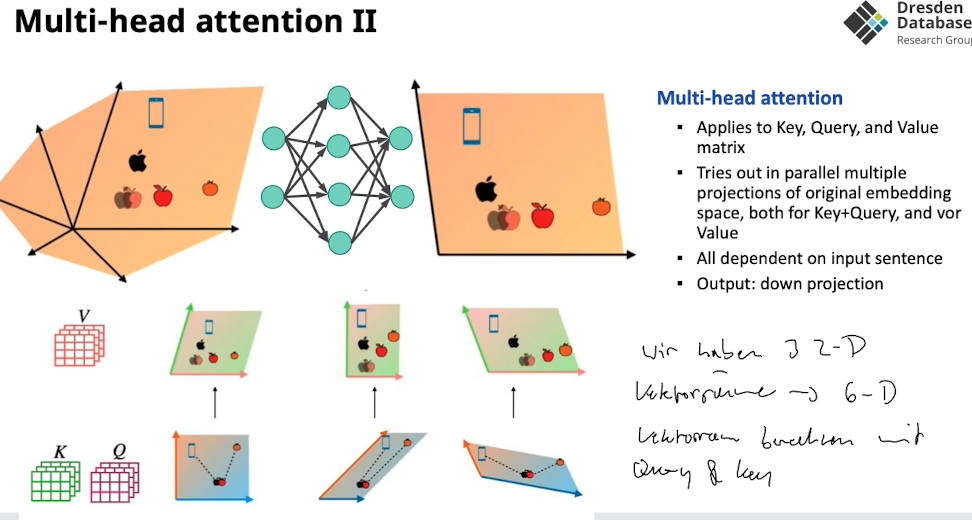
- wir probieren dann 3 verschiedene diese Matrizen aus unschauen was den besten score hat → wie genau das erlernt das Netzwerk → “Multi head attension”
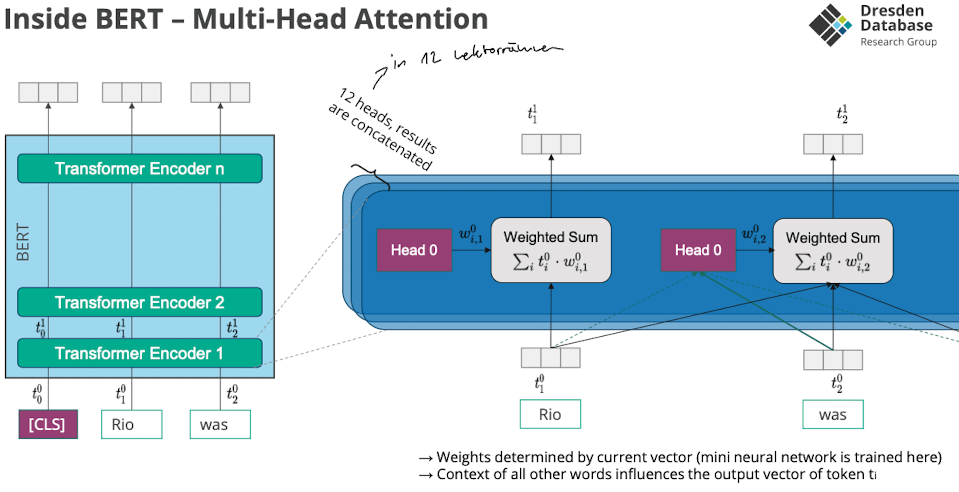
Multi-Head Attension
- Multiple key+value metrices
- werden parallel berechnet
- multiple lineare transformationen
- Network assigns score how good the good linear transformations are for current input
- final embedding ist weighted combination of all anhand der bewertung
Value Matrix
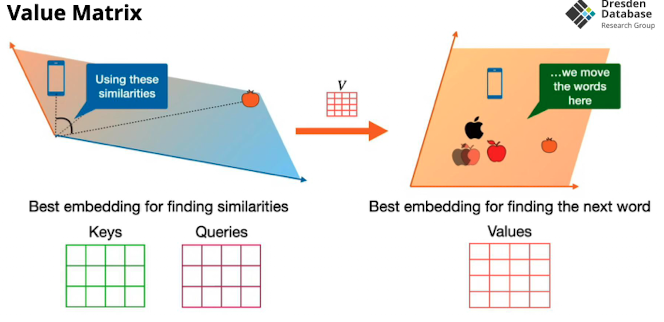
- wir nehmen nicht einfach die Distanz sondern das verschieben im Vektorraum machen wir mit einer zu erlendenden Matrix
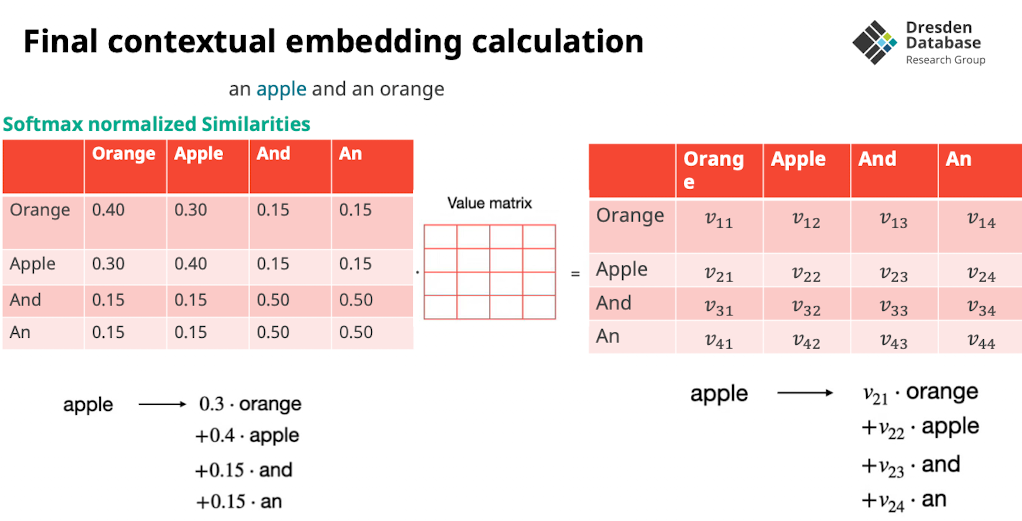
- wie nehmen alle 2D Vektorräume und konkatennieren den um alle linearen transformationen auf einmal machen können
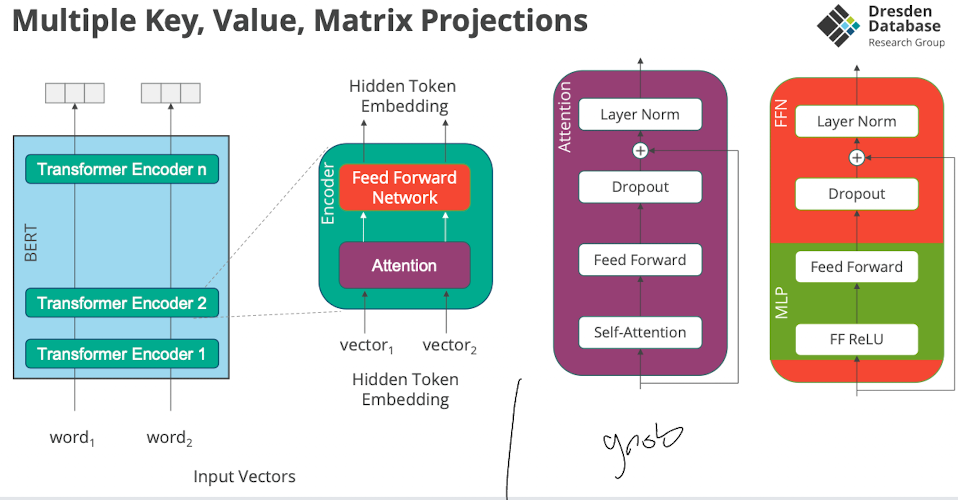
Transformer Architecture
Transformer
- reich grob..
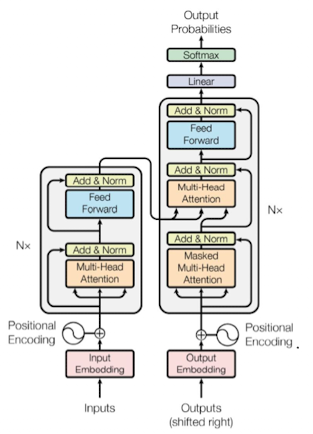
- Was ist das
- ist eine Model Architektur von Neuralen Networks
- linke Seite encode
- trainiert um sprache zu verstehen
- rechte Seite decoder
- trainiert um sprache zu generieren
- Decorder
- sinnvoll für completions, generation, translation, querstion answering
- sinnvoll für completions, generation, translation, querstion answering
- Encoder
- sinnvoll für text classifizierung, wird genutzt wenn input sequence hat eine bedeutung als ganzes
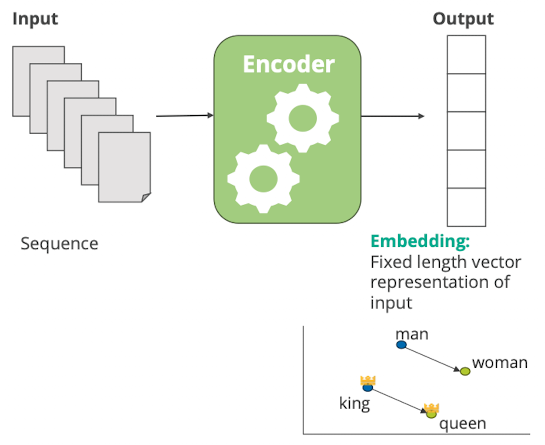
- sinnvoll für text classifizierung, wird genutzt wenn input sequence hat eine bedeutung als ganzes
BERT
…ist eine konkrete Implementierung eines encoders…
Idea
Wir geben text hinein → bekommen Embeddings mit Kontext
- Bidirectional Encoder Representations from Transformers
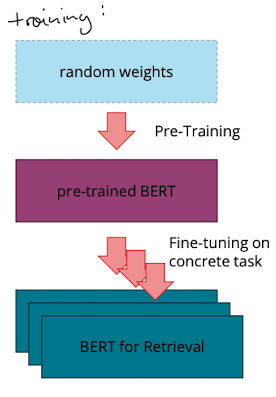
- Funktion: es nimmt eine sequenz von tokens und gibt eine sequenz von vektoren zurück
- für jedes Wort ist Satzverständnis drin
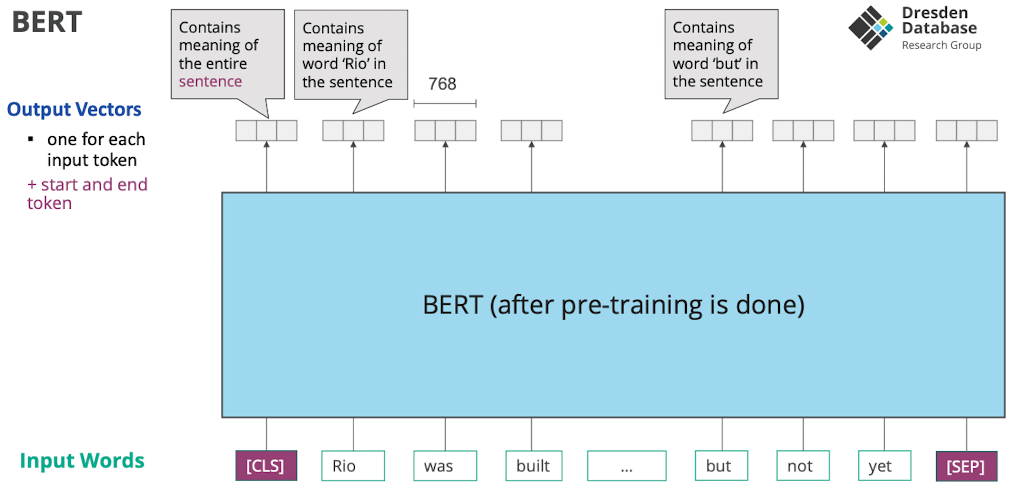
- Ablauf
- Input Satz: “how can i evaluate $ \sum_{n=1}….
- Byte Pair Encoding: Wörter auf token mappen, häufige Wörter bekommen eigene token dinge die selten sind werden zusammengesetzt
- Dann CLS und SEP Token hinzufügen
- Tokens zu ids

- Dann forward pass
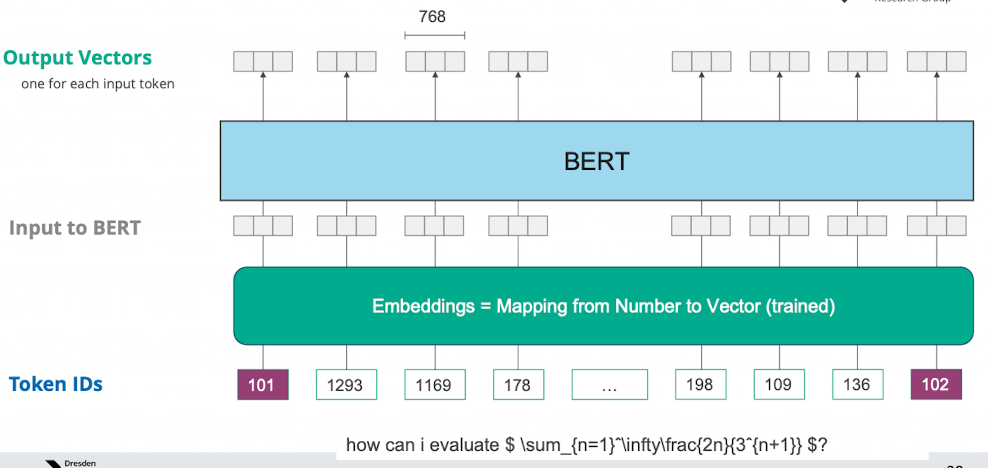
- bzw. anfängliches Embedding (aus 3 sub) wird mit Kontext angereichert
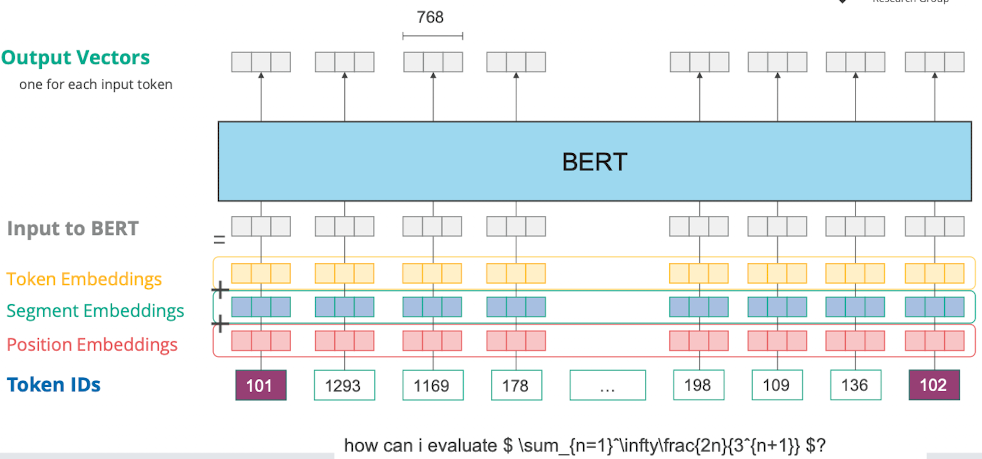
- bzw. anfängliches Embedding (aus 3 sub) wird mit Kontext angereichert
Positional Encoding
- wir wollen die position des wortes im Satz irgendwie darstellen, wir im vektorraum als richtung abgebildet
Inside BERT
- Word embedding mehrfach hin und her verschieben durch multiple attension

Why does this work?
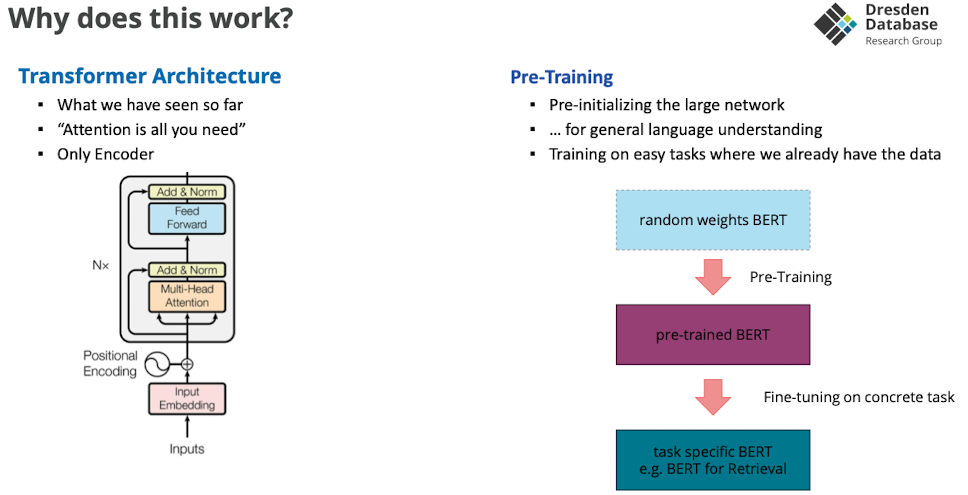
Training phase for Transformer Models
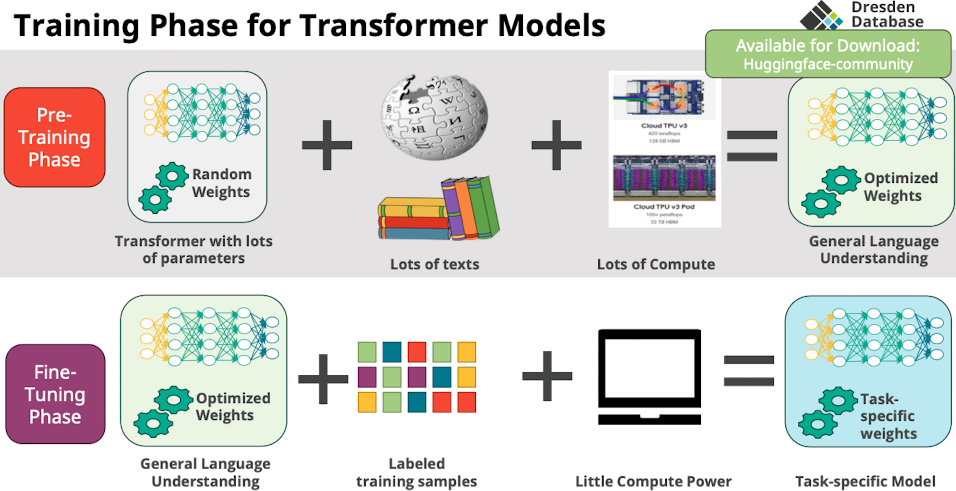
- Warum pre training?
- wieder, flatter, areas with smaller generalization error
- startpunkte sind schon bisschen sinnvoller, auch mit weniger gelabelten daten, schneller minimum finden
- rechenaufwendiges wird von anderen gemacht → nur anpassen
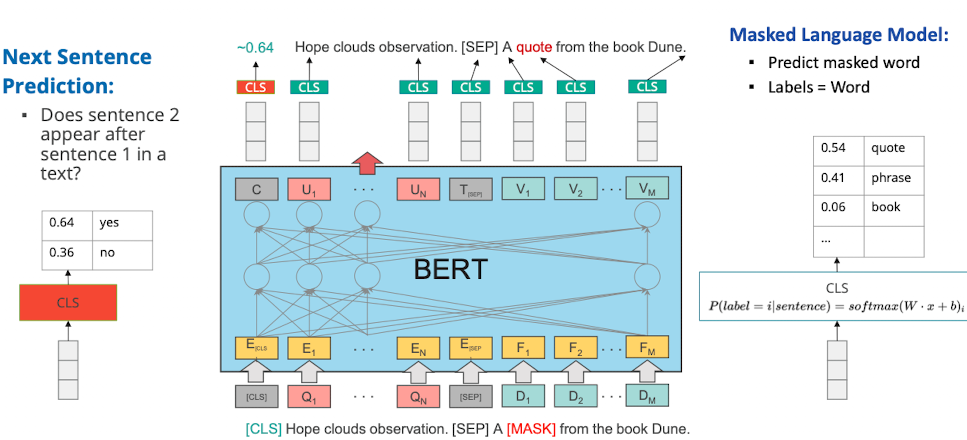
BERT Pre-Training Task
- ähnlich wie word2vec
- gibt eine Menge an tasks mit denen wir das modell trainieren können
- zB maskieren, nächsten satz predicten
Block 3: transformer for IR
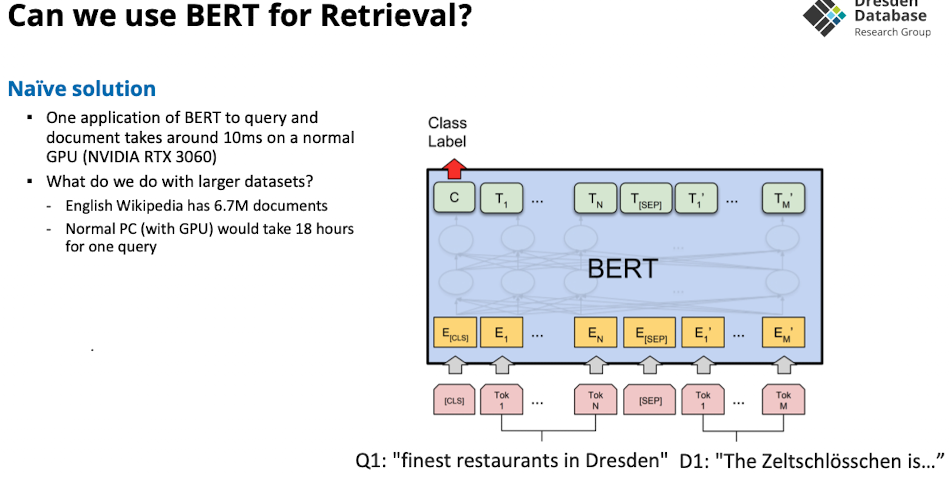
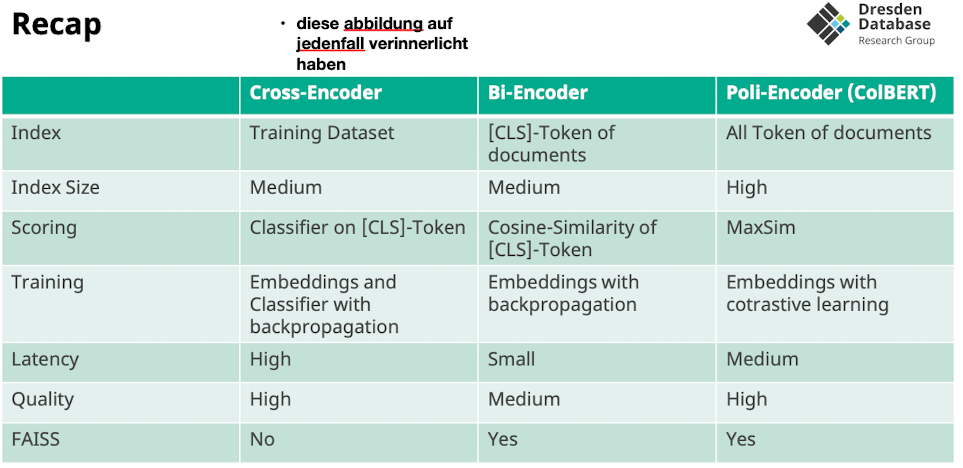
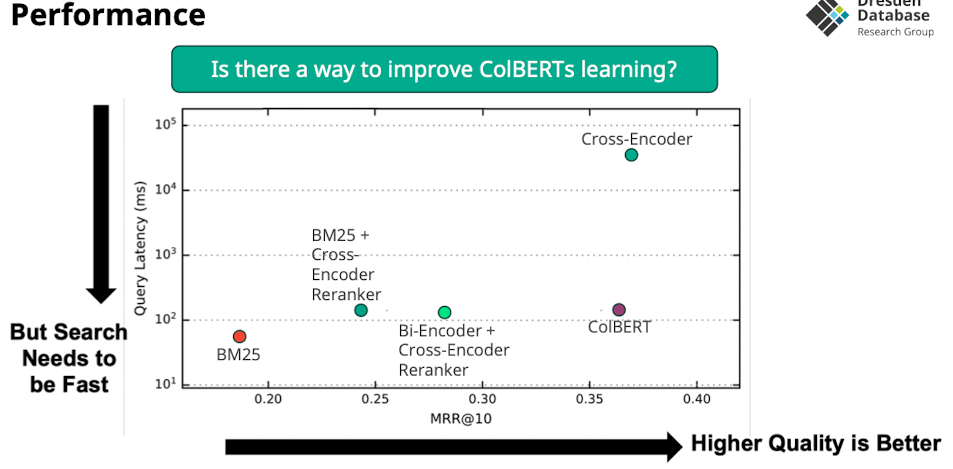
Cross-Encoder
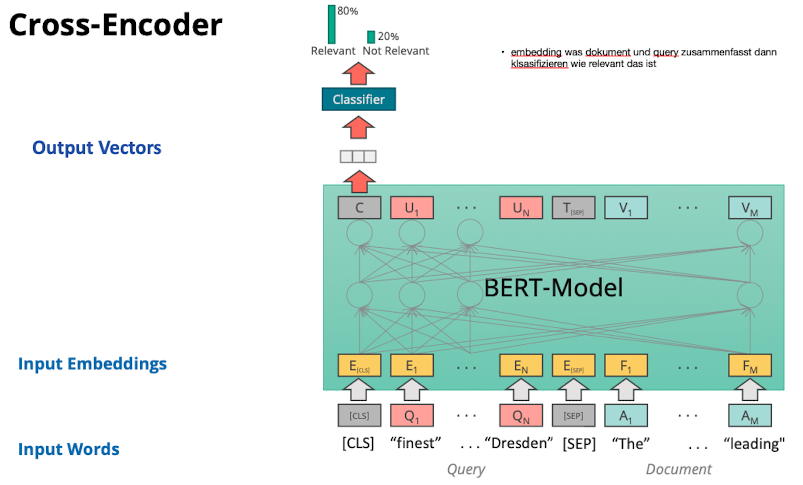
Cross-Encoder: Training of the BERT Model
- um das CLS Token mit bedeutung zu erstellen muss der cross encoder die sprache verstehen
- BERT Model mit maskierung und next sentence Prediction trainieren
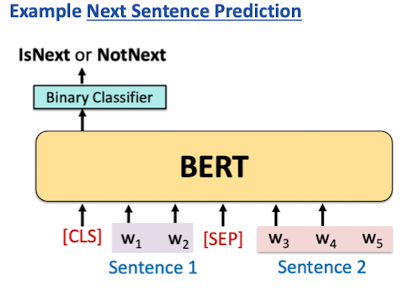
- oder: ein pre trained language model benutzen
- BERT Model mit maskierung und next sentence Prediction trainieren
Cross-Encoder: Training the Classifier
- er muss das CLS interpretieren um ein relevanz score zu erstellen
Cross-Encoder
- Wie scoren wir?
- BERT auf konkatenierte query + document
- trainierter classifier sagt die relevance document zum CLS token
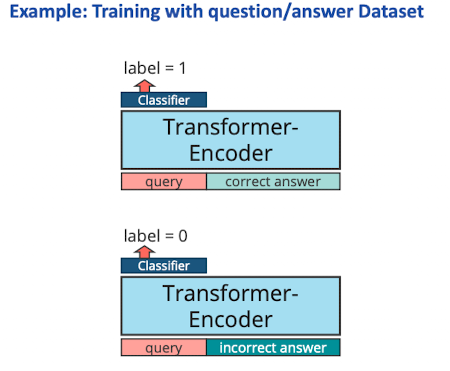
- Wie trainieren wir?
- pre-trained models und embeddings tunen
- für IR auf question answer dataset
- Retrival Time?
- slow weil jedes document als query-document paar abgelegt werden muss
- 1 query 10ms, auf großen datensatz 18h…
- Qualität?
- sehr gut
- Index: haben wir keinen, sondern nur trainings datensatz
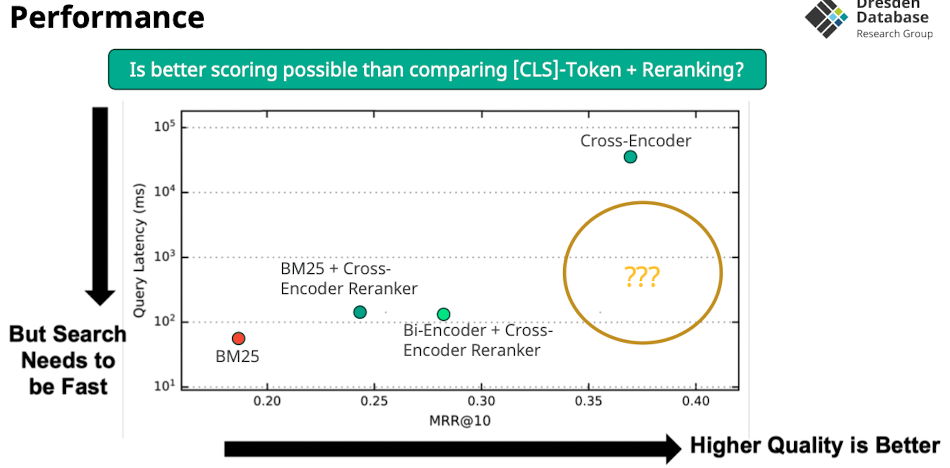
A Simple Search Engine
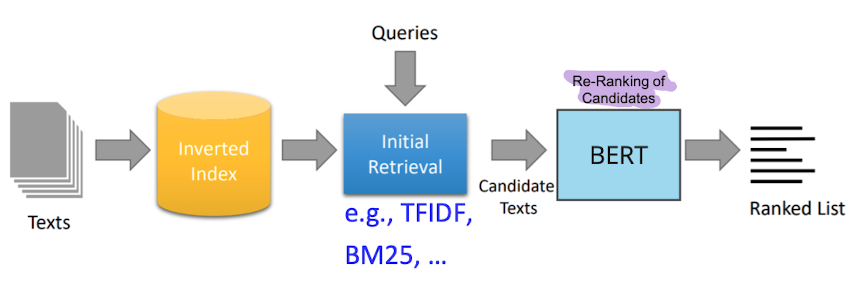

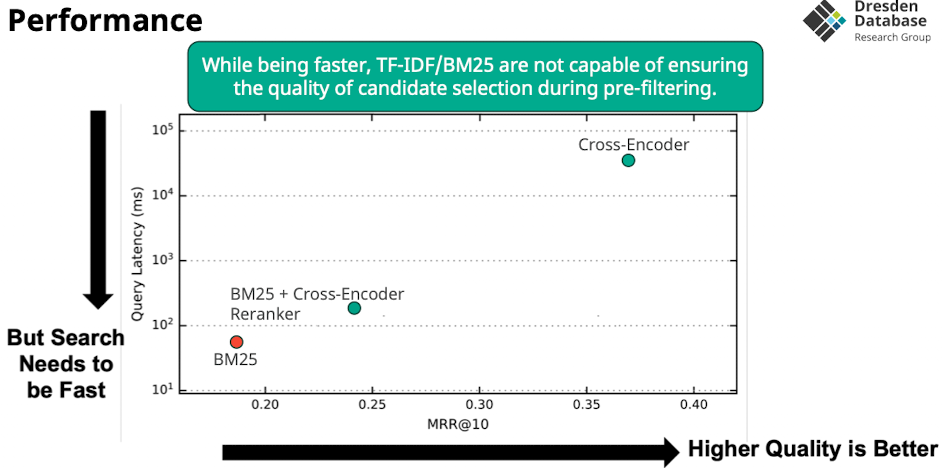
Bi-Encoder
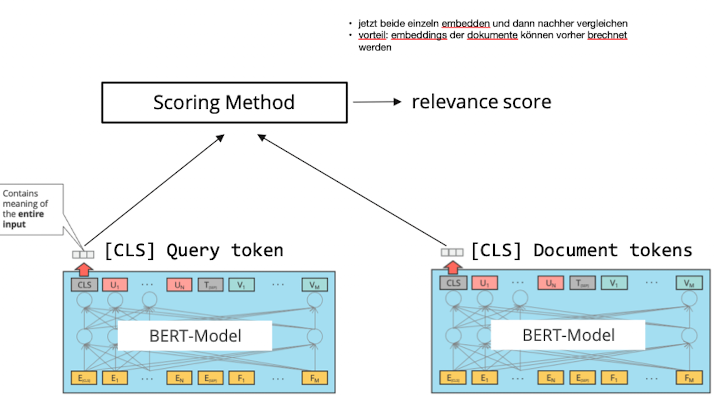
- Bi Encoder verlgiecht CLS Token von query mit document für scoring
- CLS der dokumente kann vorberechnet werden
- scoring möglich mit
- Cosisne, Dot Product, Euclidean Distance
- Aber: ist nicht so fine granular wie die Cross Encoder
- Late interaction: erst wenn query kommt interagieren beide
- Keine attention zwischen query und document (weniger quali)
- Das scoring ist sehr schnell machbar
- Idee: warum nicht mit alle anderen dokumenten scoren statt nur die vielversprechenden
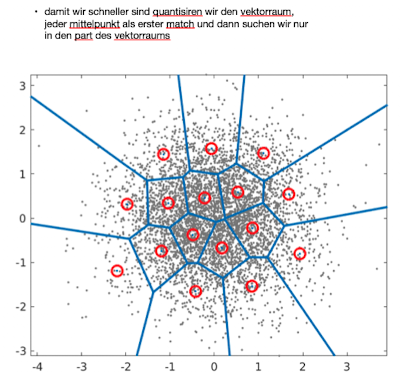
Bi-Encoders: Speed through Vector Quantization
- Idee: scoring für die nearest neighbors vector quantization berechnen
- Bi-Encoder

Poly-Encoder
ColBERT
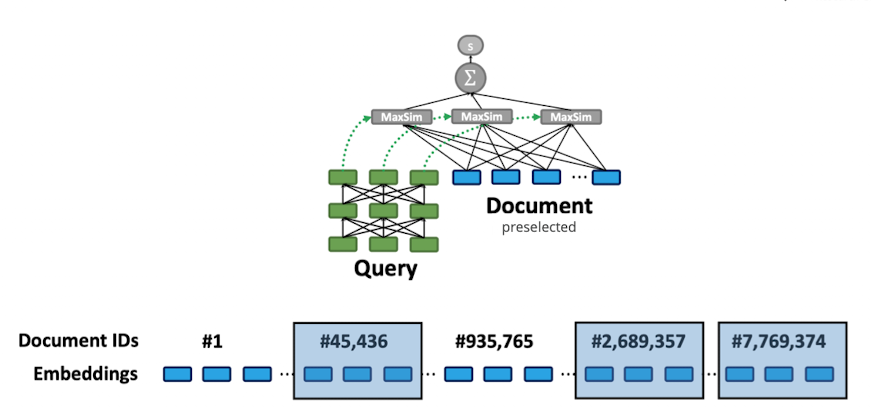
- hier auch pre encoding aller dokumente (wie Bi-Encoder)
- Fine Grained Representation
- Late interaction: Query and document only interact while calculating scoring for the query
- MaxSim: clever way to compare Token-Embeddings after encoding
- ColBert
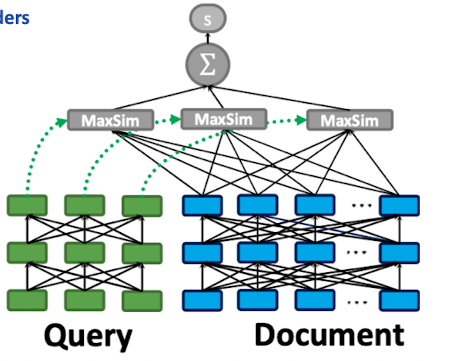
- Scoring query mit dokument
- jedes query token scored einzeln
- jedes query token machted best scoring document-token des dokuments
- scoring via cosine-similarity
- speedup via vector quantization
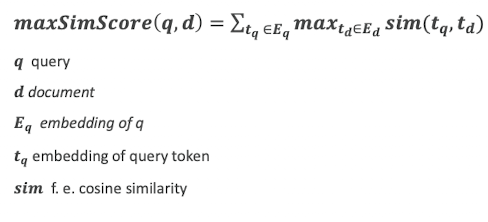
- jeder Teil der Suchanfrage kann sich auf anderen Teil des Dokumente konzentrieren
- bekommen score top 5 für jedes wort der query
- die nehmen wir zusammen
- dann wiederrum die top 5
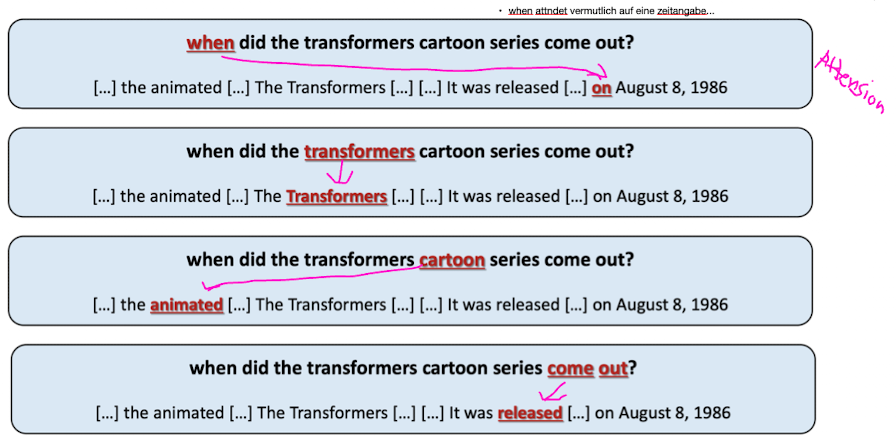
- erstes Wort der Query (embedding) auf welche wörter von dokumenten attended das
- dann top 5 des query tokens
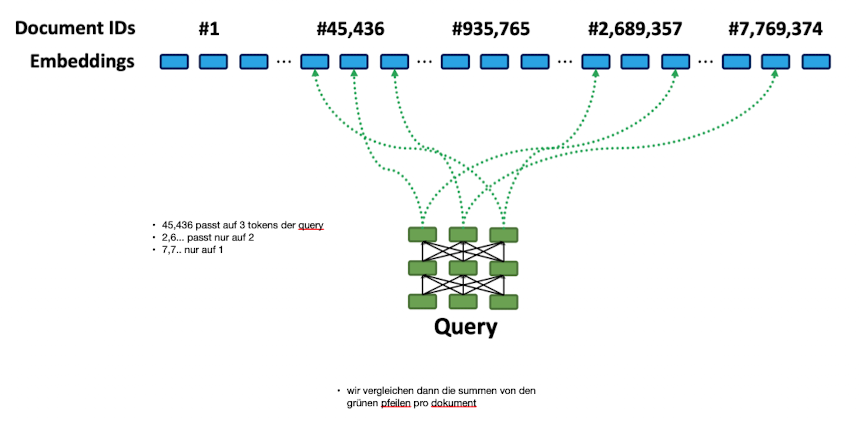
- Erklärung der Formel die wir anwenden:
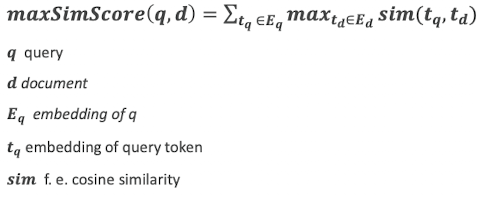
- wir bilden am Ende die Ähnlichkeit der tokens von query mit tokens vom dokument
- aus diesen nehmen wir das token heraus wo wir die größte ähnlichkeiten haben → für jeden query token suchen wir den token aus allen dokumenten mit dem wir am höchsten attenden
- dann bilden wir die summe über diesen similarities
- die können wir dann wieder ranken
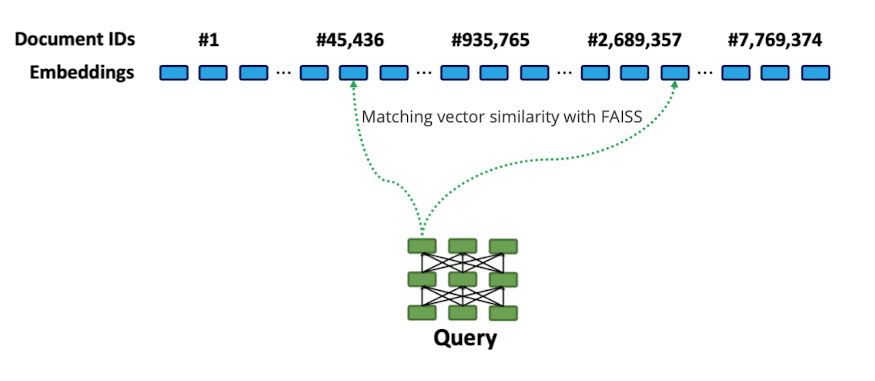
- das machen wir dann für jeden token der query
- wir sehen das #45,436 auf alle drei aspekte attended
- da wir summe nehmen für das auswählen der top k, kommt das tendenziell besser weg wo mehr drauf attended
What to use for pre training
- je nachdem was uns die domäne gibt (source code , saxon, japanese)
- dinge wie bert base large als gute grundlage
- ColBERT index ist groß - für wikipedia zB 650 GB
- aber durch vectorisierung gut suchen → skaliert trd

How to Fine Tune Colbert: Contrastive Learning Paradigm
- Model mit maximal schwierige Trainingsbeispiele dazu bringen möglichst gut diese unterscheidungsentscheidungen machen zu können
Training data
- Tripel: Query, positive & negative Answer
- Was kann getunt werden?
- Gewichte für wort embeddings
- Gewichte für encoder layer
- Projection of embeddings into space
Loss Function

Normal Training


- wir nehmen nicht alle negativen sondern nur ein spezielles “hard negative”

Training mit Hard Negatives
- um training zu reduzieren und lerneffekt stark möglichst schwere beispiele nehmen
- model lernt auf kleine dinge zu achten

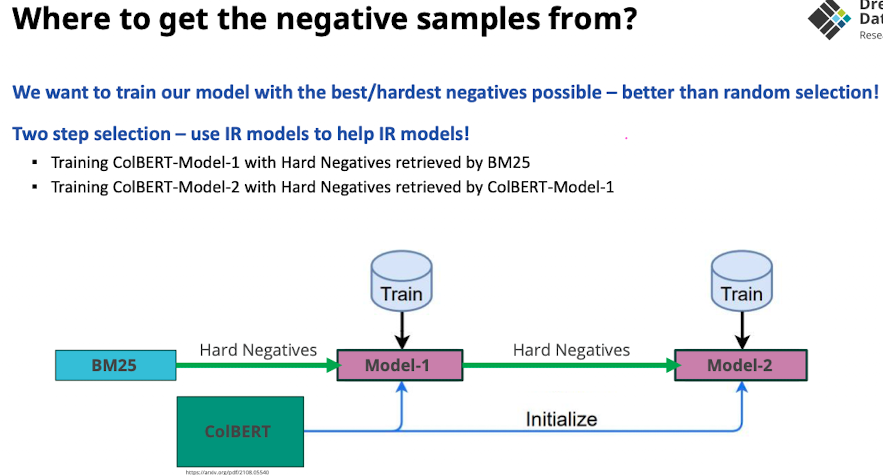
“InDi: Informative and Diverse Negatives Improving the selection of Hard Negatives - Cohen”

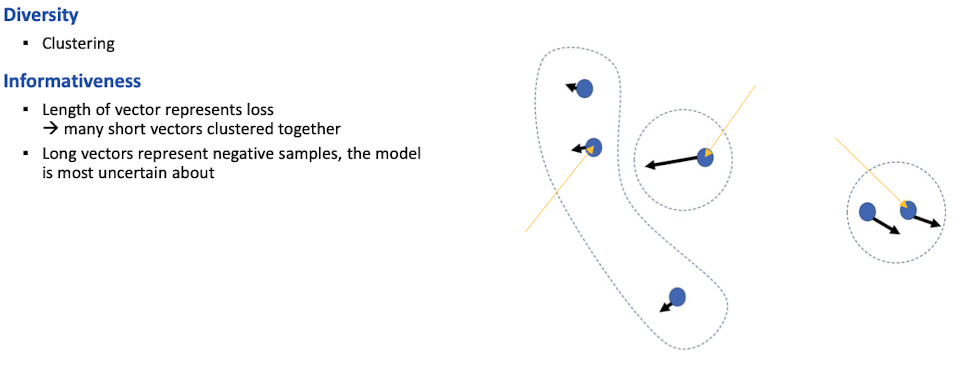
- Idee: Gradienten nutzen um den Fehler des dokuments zu finden, Richtung zeigt “wie schwierig ist es für das modell die ähnlichkeit zu bestimmen”
- richtungen clustern mit k-means
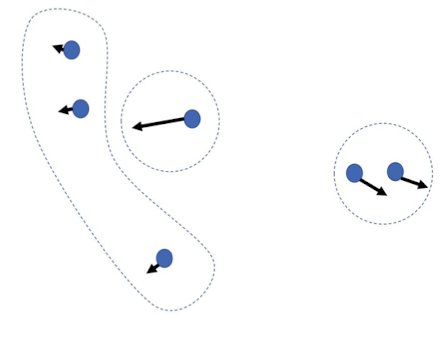
- dann unterschiedlichen richtungen ruassuchen via medoid als negative (vector closest to center)
- richtungen clustern mit k-means
Problems with InDi
False Negatives
- wenn dinge nicht als positive gelabelt sind → kann passieren das diese fälschlicherweise als negativ beispiel genommen werden

PRÜ: Recap Encoders